Overview:
- A powerful quantitative analysis method was created as a result of the Manhattan Project and named for an exotic casino popularized by the James Bond series
- The tool is the most practical and efficient way of simulating thousands of scenarios and calculating the most likely outcomes
- Unlike other methods, this tool incorporates randomness that is found in real-world decisions
- Using this method doesn’t require sophisticated software or advanced training; any organization can learn how to use it
A nuclear physicist, a dashing British spy, and a quantitative analyst walk into a casino. This sounds like the opening of a bad joke, except what all of these people have in common can be used to create better decisions in any field by leveraging the power of probability.
The link in question – that common thread – gets its name from an exotic locale on the Mediterranean, or, specifically, a casino. James Bond visited a venue inspired by it in Casino Royale, a book written by Ian Fleming, who – before he was a best-selling author – served in the British Naval Intelligence Division in World War II. While Fleming was crafting creative plans to steal intel from Nazi Germany, a group of nuclear physicists on the other side of the Atlantic were crafting plans of their own: to unleash the awesome destructive power of nuclear fission and create a war-ending bomb.
Trying to predict the most likely outcome during a theoretical nuclear fission reaction was difficult to say the least, particularly using analog computers. To over-simplify the challenge, scientists had to be able to calculate whether or not the bomb they were building would explode – a calculation that required an integral equation to somehow predict the behavior of atoms in a chain reaction. Mathematicians Stanislaw Ulam and John Von Nuemann, both members of the Manhattan Project, created a way to calculate and model the sum of thousands of variables (achieved by literally placing a small army of smart women in a room and having them run countless calculations). When they wanted to put a name to this method, Ulam recommended the name of the casino where his uncle routinely gambled away large sums of money<fn>Metropolis, N. (1987). The Beginning of the Monte Carlo Method. Los Alamos Science, 125-130. Retrieved from https://permalink.lanl.gov/object/tr?what=info:lanl-repo/lareport/LA-UR-88-9067</fn>.
That casino – the one Fleming’s James Bond would popularize and the one where Ulam’s uncle’s gambling addiction took hold – was in Monte Carlo, and thus the Monte Carlo simulation was born.
Now, the Monte Carlo simulation is one of the most powerful tools a quantitative analyst can use when incorporating the power of probabilistic thinking into decision models.
How a Monte Carlo Simulation Works – and Why We Need It To
In making decisions – from how to make a fission bomb to figuring out a wager in a table game in a casino – uncertainty abounds. Uncertainty abounds because, put simply, a lot of different things can happen. There can be almost-countless scenarios for each decision, and the more variables and measurements are involved, the more complicated the calculations become to try and figure out what’s most likely to happen.
If you can reduce possible outcomes to a range of probabilities, you can make better decisions in theory. The problem is, doing so is very difficult without the right tools. The Monte Carlo simulation was designed to address that problem and provide a way to calculate the probability of thousands of potential outcomes through sheer brute force.
Doug Hubbard provides a scenario in The Failure of Risk Management that explains how a Monte Carlo simulation works and can be applied to a business case (in this context, figuring out the ROI of a new piece of equipment). Assume that you’re a manager considering the potential value of a new widget-making machine. You perform a basic cost-benefit analysis and estimate that the new machine will make one million widgets, delivering $2 of profit per unit. The machine can make up to 1.25 million, but you’re being conservative and think it’ll operate at 80% capacity on average. We don’t know the exact amount of demand. We could be off by as much as 750,000 widgets per year, above or below.
We can conceptualize the uncertainty we have like so:
- Demand: 250,000 to 1.75 million widgets per year
- Profit per widget: $1.50 to $2.50
We’ll say these numbers fall into a 90% confidence interval with a normal distribution. There are a lot of possible outcomes, to put it mildly (and this is a pretty simple business case). Which are the most likely? In the book, Doug used an MC simulation to run 10,000 simulations – or 10,000 scenarios – and tallied the results for each (with each scenario representing some combination of demand and profit per widget to create a loss or gain). The results are described by two figures: a histogram of outcomes (figure 1) and a cumulative probability chart (figure 2)<fn>Hubbard, D. W. (2009). The failure of risk management: Why its broken and how to fix it. Hoboken, NJ: J. Wiley & Sons.</fn>:
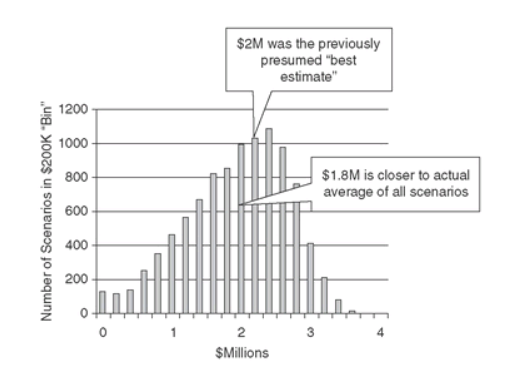
Figure 1: Histogram of Outcomes

Figure 2: Cumulative Probability Chart
You, the manager, would ideally then calculate your risk tolerance and use this data to create a loss exceedance curve, but that’s another story for another day. As Doug explains, using the MC simulation allowed you to gain critical insight that otherwise would’ve been difficult to impossible to obtain:
Without this simulation, it would have been very difficult for anyone other than mathematical savants to assess the risk in probabilistic terms. Imagine how difficult it would be in a more realistically complex situation.
The best way to sum up the diverse benefits of incorporating MC simulations into decision models was written by a group of researchers in an article titled “Why the Monte Carlo method is so important today”:<fn>Kroese DP, Brereton T, Taimre T, Botev ZI. Why the Monte Carlo method is so important today. Wiley Interdisciplinary Reviews: Computational Statistics 2014; 6( 6): 386– 392.</fn>
- Easy and Efficient. Monte Carlo algorithms tend to be simple, flexible, and scalable.
- Randomness as a Strength. The inherent randomness of the MCM is not only essential for the simulation of real-life random systems, it is also of great benefit for deterministic numerical computation.
- Insight into Randomness. The MCM has great didactic value as a vehicle for exploring and understanding the behavior of random systems and data. Indeed we feel that an essential ingredient for properly understanding probability and statistics is to actually carry out random experiments on a computer and observe the outcomes of these experiments — that is, to use Monte Carlo simulation.
- Theoretical Justification. There is a vast (and rapidly growing) body of mathematical and statistical knowledge underpinning Monte Carlo techniques, allowing, for example, precise statements on the accuracy of a given Monte Carlo estimator (for example, square-root convergence) or the efficiency of Monte Carlo algorithms.
Summarized, Monte Carlo simulations are easy to use, not only help you more closely replicate real-life randomness but understand randomness itself, and are backed by scientific research and evidence as to how they make decision models more accurate. We need them to work because any significant real-world decision comes with a staggering amount of uncertainty, complicated by thousands of potential outcomes created by myriad combinations of variables and distributions – all with an eminently-frustrating amount of randomness haphazardly mixed throughout.
How to Best Use a Monte Carlo Simulation
Of course, knowing that an MC simulation tool is important – even necessary – is one thing. Putting it into practice is another.
The bad news is that merely using the tool doesn’t insulate you from a veritable rogue’s gallery of factors that lead to bad decisions, ranging from overconfidence to using uncalibrated subjective estimates, falling victim to logical fallacies, and making use of soft-scoring methods, risk matrices, and other pseudo-quantitative methods that aren’t better than chance and frequently worse.
The good news is that all of those barriers to better decisions can be overcome. Another piece of good news: you don’t need sophisticated software to run a Monte Carlo simulation. You don’t even need specialized training. Many of the clients we train in our quantitative methodology don’t have either. You can actually build a functional MC simulation in native Microsoft Excel. Even a basic version can help by giving you more insight than you know now; by giving you another proven way to glean actionable knowledge from your data.
On its own, though, a MC simulation isn’t enough. The best use of the Monte Carlo method is to incorporate it into a decision model. The best decision models employ proven quantitative methods – including but not limited to Monte Carlo simulations – to follow the process below (figure 3):
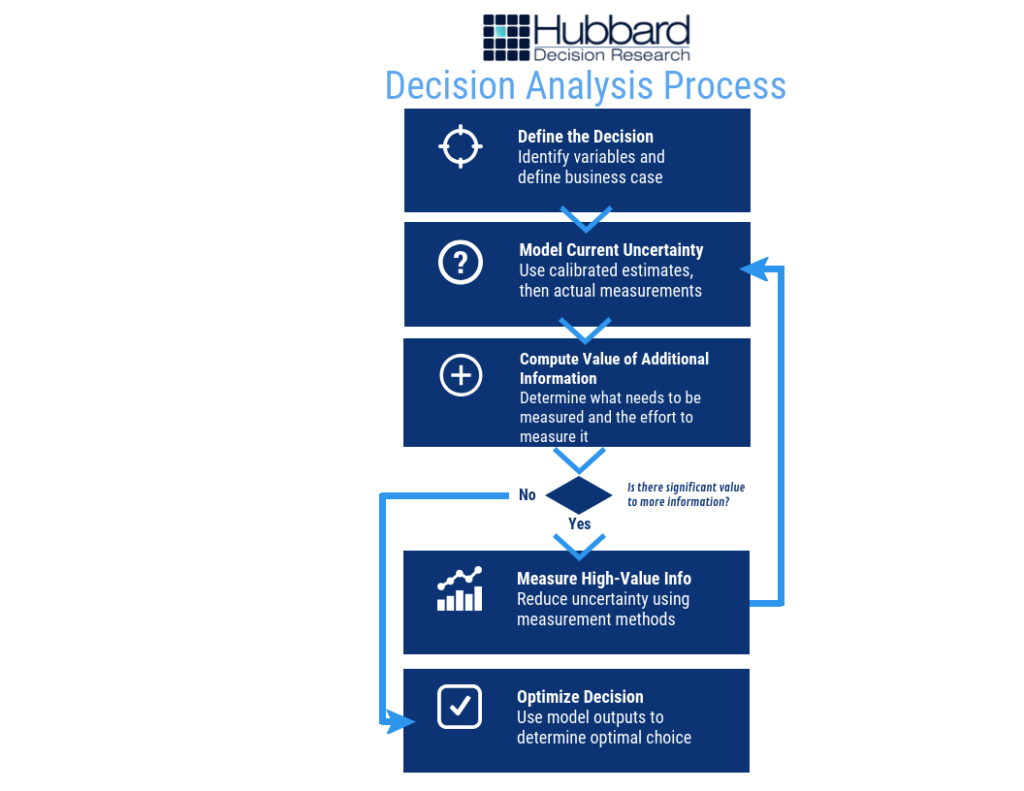
Figure 3: HDR Decision Analysis Process
The outputs of a Monte Carlo simulation are typically shown in that last step, when the model’s outputs can be used to “determine optimal choice,” or, figure out the best thing to do. And again, you don’t need specialized software to produce a working decision model; Microsoft Excel is all you need.
You may not be creating a fearsome weapon, or out-scheming villains at the baccarat table, but your decisions are important enough to make using the best scientific methods available. Incorporate simulations into your model and you’ll make better decisions than you did before – decisions a nuclear physicist or a secret agent would admire.
Recommended Products: