Misallocation of Vaccines Leads to 75,000 Additional US Deaths…At Least
As we prepare to roll out the vaccine across the United States, we are faced with an unparalleled opportunity. But there is also a danger of squandering the opportunity. States will distinguish themselves by the speed with which they get their populations to herd immunity, and by the degree to which they minimize the number of people who die during the period when the vaccine is provided.
The number of vaccines available per month is outside of your control. Therefore, as a decision maker, the lever for affecting outcomes lies in your decisions about what order (and which of) your citizens get the vaccine. Certain populations should clearly be at the front of the line (e.g. health care workers without SARS COV2 antibodies). But many questions remain: does the benefit of knowing who has antibodies justify the cost of an antibody test? Should you prioritize people more likely to spread COVID (front-line workers) or people more vulnerable to adverse outcomes (comorbid/elderly).
Vaccination Strategies for Minimizing Deaths
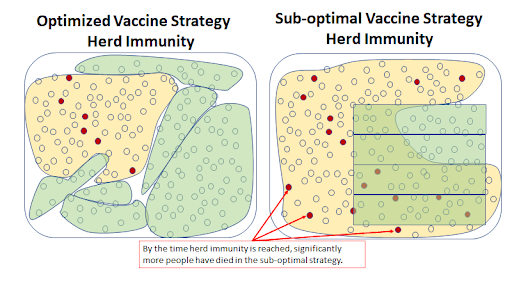
How vaccines are distributed can make a huge difference in the duration of economic effects, hospitalizations, and even deaths. Our analysis shows that nationwide an optimized distribution strategy is 90% likely to avoid more than 75,000 deaths over simpler distribution strategies. The same analysis shows that even for a medium sized state, improved vaccination strategies could reduce the duration of the pandemic by two months and could reduce the number of deaths due to COVID infection by more than 1,000 people.
This is accomplished by how we make tradeoffs among three guiding principles:
Don’t vaccinate people who have already had the infection.
Vaccinate people who are more likely to infect others.
Vaccinate vulnerable people (elderly and people with comorbidities are at higher risk of dying.)
There is extensive research indicating likelihood of reinfection is low and that infection with SARS-COV2 confers long term immunity[1][2][3][4]. One might therefore think the lowest hanging fruit would be to prioritize immunizations for the population that does not have antibodies or memory T cells for SARS-COV2. Unfortunately, only 10-20% of those who have had the illness are “visible” as indicated by a confirmed COVID test[5]. The remaining 80-90% of the already immune population is indistinguishable from the people who are not immune. So which tool should you use to reveal who is in this “not immune” population – antibody tests or statistical analysis? The answer to this question is pivotal and will probably vary from county to county and city to city. What is your current strategy to answer this question?
The other pivotal question is whether a strategy will save more lives by focusing on vaccinating socially active [6] or by focusing on vaccinating vulnerable populations? It is relatively straightforward to determine who is in the most vulnerable population (elderly and people with comorbidities) but knowing which broad strategy saves more lives is not as clear.
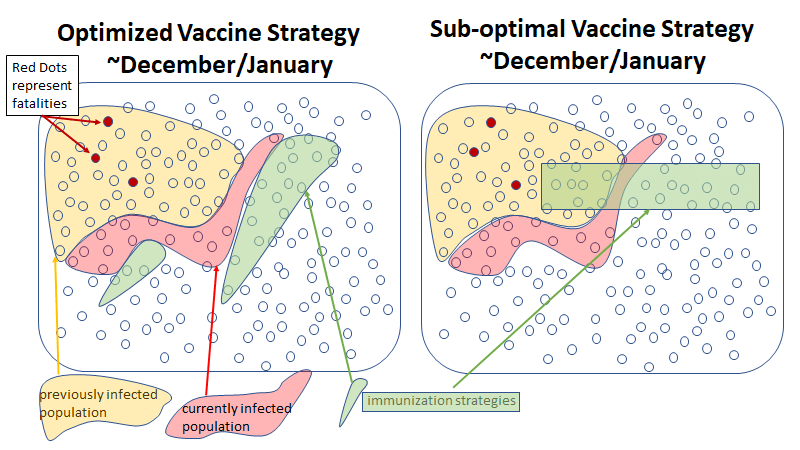
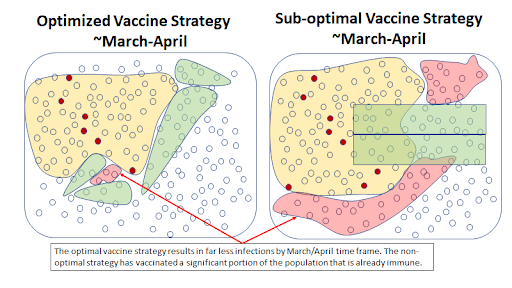
The charts below show how the virus may spread with an optimized strategy vs. a less effective strategy. In the less effective strategy, some vaccines are wasted on individuals who already have antibodies. In addition, the sub-optimal strategy would not attempt to identify recipients for the vaccine as a function of how likely they are to spread the virus to others.
The better strategy minimizes the use of vaccines on people who do not need them and focuses on individuals more likely to spread the virus to others. Because this strategy slows down the rate of spread, it also allows more time to vaccinate the population not already immune.
The costs and benefits are also not limited to directly saving lives. Since the optimal strategy would also end community transmission more quickly, there would be economic benefits as well. For a medium sized state like Wisconsin, economic benefits would run in the billions of dollars (think opening a convention center 45 days before your neighboring states are able to do so). For the same state, the cost of getting the order wrong is a thousand or more (preventable) COVID deaths and a society shut down for 1 month+ longer than need be. As a decision maker for vaccine distribution, you get to decide whether to be seen as the hero…or the villain. But to be the hero, you need the right tools.
How Hubbard Decision Research Can Help
For 20+ years, Hubbard Decision Research has been “spreading the gospel” about probabilistic methods across many areas of industry and government. Probabilistic forecasting has been shown to yield the best results across all the industries where it has been measured and studied. We have the experience and expertise to bring these methods into any organization and any challenge. This year, HDR has also built a reputation for accurate forecasting and predictions with COVID related issues for businesses and municipalities, as well as national forecasting. We have presented webinars for the GFOA, and worked on COVID related operational risk projects for school districts, insurance and reinsurance companies, and a variety of other industries. Our Applied Information Economics methodology has been applied across industries, government, and the military and focuses on improving decisions through probabilistic modeling.
Turn your vaccine distribution solution into an optimized quantitative solution. HDR offers a 20% discount on our rates for governments and nonprofits. Contact us to learn more.
Watch the interview with BSW that was previously aired on Tuesday, August 4th at 6:30pm CDT. Doug talks about his ground shaking exposé on the failure of popular cyber risk management methods, How To Measure Anything in Cybersecurity. This particular book is a Palo Alto Networks Cybersecurity Canon Award winner and the first of a series of spinoffs from his successful first book, How To Measure Anything: Finding the Value of “Intangibles” in Business. It is cited by the Center for Internet Security RAM Version 1.0 as a “thorough and practical guidance on using probability analysis for cybersecurity decision making.”
In the interview, Doug talks about his life’s work which is about building better “business impact” decision makers in any department of any sized organization and in any industry. He has sold over 150,000 copies of four different books in eight different languages. He offers powerful online training and consulting services revolving around his quantitative methodology, Applied Information Economics (AIE), for his global client base of Fortune 500 companies, federal and state governments, the United States military, and major non profits including the United Nations.
For this interview, Doug is particularly pleased with his shirt choice! Enjoy!
We heard you loud and clear and are happy to accommodate! We are extending our promotional offer on the NEW AIE Analyst Series through Friday, August 28th. Receive a dollar-for-dollar discount of all your previous webinar expenditures with HDR, up to 75% off the price of the new AIE Analyst Series, per person – if you book by Friday, August 28th.
The new AIE Analyst Series regular price is $1,950. This means you could take the entire series for as little as $487.50, if you have at least $1,462.50 in previous webinar expenditures. If you have more than $1,462.50 is previous webinar expenditures, invite a friend or colleague and (based on your remaining spend) they could also receive up to 75% off the series as well. This offer includes recordings of all courses in the series and access to online materials, even if you are unable to attend some or all of the live workshops.
Regular Prices on new courses included in the AIE Analyst Series:
Calibrated Probability Assessments – $580 (Pandemic Price: $325)
Creating Simulations in Excel: Basic – $375 (Pandemic Price: $310)
Creating Simulations in Excel: Intermediate – $375 (Pandemic Price: $310)
One Elective Course – $150 (Pandemic Price: $95)
(For Elective Course, Choose from: HTMA in Project Mgt, HTMA in Innovation, HTMA in Cybersecurity Risk, Failure of Risk Management)
Even courses that were part of the previous AIE Analyst series, such as Decisions Under Uncertainty and Empirical Measurements, have new methods and new spreadsheet tools. And now the new Computer Based Training (CBT) components mean that you can review hours of content online at your own pace and take the review quizzes online.
If you have any questions or if you are interested to take advantage of this offer, please contact us at info@hubbardresearch.com to verify your previous webinar expenditures and to receive your unique promo code in order to claim your personalized discount at checkout.
HDR is honored to partner with QA. QA is the UK’s biggest training provider of virtual, online and classroom training in technology, project management and leadership. HDR will provide a “taster” event on quantifying IT/Cyber Risk on August 19th and August 20th.
Day 1: In this first session, we identify the widespread lack of quantitative IT risk analysis in (UK) organizations and the dangers posed by relying on risk matrices. Doug will then explain how our quantitative approach of AIE (Applied Information Economics) can help you make better, cost-effective risk analysis, which measurably reduce uncertainty and risk.
Date: Wednesday 19 August 2020
Time: 6:30am – 7:30am CDT
Cost: FREE
Day 2: Analyzing risk always involves a degree of subjectivity and associated uncertainty. In this session we focus how to estimate that uncertainty and how to reduce it – two essential activities in quantitative risk analysis. We do this by reviewing the results of the exercise given at the end of the previous session. We identify some of the obstacles to estimating uncertainty and show how you can be calibrated to overcome these obstacles and make better estimates.
Doug Hubbard is the CEO of Hubbard Decision Research, founded in 1998. It provides consultancy and training in quantitative methods to support decision making. He is the creator of AIE (Applied Information Economics) whose principles underpin this quantitative approach. These methods have been adopted by businesses across many sectors and by government organizations.
Doug started his career as a management consultant at Coopers and Lybrand after gaining his MBA in 1988. As well as providing management consultancy, he is a sought-after speaker and the author of a number of books, including The Failure of Risk Management: Why It’s Broken and How to Fix It, How to Measure Anything: Finding the Value of “Intangibles” in Business and How to MeasureAnything in Cybersecurity Risk. The first two books are now set texts for exams for membership of the Society of Actuaries. His articles and research have also been published in a number of periodicals and learned journals, including Nature, The IBM R&D Journal, and The American Statistician.
Fred Hickling
Fred Hickling is a cybersecurity consultant and a QA associate trainer. Over the years, he has become aware of how little quantitative IT risk assessment is done in the UK. Introduced to Doug Hubbard’s work last year, he appreciated the extent to which this lack was a problem, as well as a way to fix it. He introduces this event – a step in bringing the benefits quantitative risk assessment to the attention the IT professionals in the UK.
Fred is a director of Networks and Systems Ltd, as well as being a non-executive director of another company not in the IT sector. He has numerous industry certifications, including CISSP, CISM, CISMP and CCISO, as well as several physics degrees.
The Failure of Risk Management 2E is yet another in a string of very popular publications written by Doug Hubbard. Doug’s books are used as textbooks in dozens of prestigious university courses at the graduate level. His first book is required reading for the Society of Actuaries exam prep and one of the all-time, best-selling books in business math. His fourth book is a Palo Alto Networks Cybersecurity Canon award winner.
How to Measure Anything: Finding the Value of Intangibles in Business (one of the all-time, best-selling books in business math)
The Failure of Risk Management: Why It’s Broken and How to Fix It (1E/2E)
Pulse: The New Science of Harnessing Internet Buzz to Track Threats and Opportunities
How to Measure Anything in Cybersecurity Risk (co-authored with Richard Seiersen & won the Palo Alto Networks Cybersecurity Canon award)
Take a look at this short video to see what they’re saying about The Failure of Risk Management 2E. Be sure to use the pause button to catch all the details and learn more interesting facts about Doug’s writing below the video.
Doug is also published in the prestigious science journal, Nature, in addition to publications as varied as The American Statistician, CIO Magazine, Information Week, DBMS Magazine, Architecture Boston, OR/MS Today, The IBM Journal of Research & Development and Analytics Magazine.
Doug Hubbard and his team’s work is mentioned in high regard often in articles, by peers and clients alike. Perhaps it’s because HDR utilizes native Excel to create custom automation models for each client’s specific needs – without any limitations of an existing software solution and without annual licensing or subscription fees that often come along with traditional software solutions.
This week an article in InfoSec 2020 was brought to our attention where Doug is mentioned specifically by the Union Pacific CISO, Rick Holmes. Union Pacific is the second largest railroad system in the United States and is one of the largest transportation companies in the world.
A portion of the article reads, “UP assesses and analyzes risk from four different perspectives – those of an insurance company or actuarial expert, a compliance auditor, a legal advisor and the mind of an attacker. Key to the process, however, is the risk probability modeling that the cyber risk assessment team developed in order to statistically convey to upper management the likelihood of a cyber event occurring and the calculable monetary loss that would result.
For this, UP recruited management consultant and author Douglas Hubbard, who helped devise a framework that analyzed and categorized UP’s computing environment into various asset classes.”