
“It’s not what we don’t know that hurts, it’s what we know for sure that just ain’t so.”
The quote above is often attributed to Mark Twain. Ironically, the authorship of this quote being somewhat uncertain, beautifully illustrates the very point it makes. Nevertheless, the quote accurately describes the dangers of humans being overconfident. Put into quantitative terms, being overconfident is assigning higher probabilities to items than what should be the case. For example, if I’m asked to give a 90% confidence interval for 100 questions, the correct answers should be between my stated bounds 90% of the time. If it is less than 90%, I’m overconfident, and if it’s more than 90% I’m underconfident.
There have been many peer-reviewed papers on this topic that reveal humans, regardless of field or expertise, are broadly overconfident in providing probabilistic estimates. Data collected by HDR on calibration performance supports this conclusion. When participants prior to any sort of training were asked to provide 90% confidence intervals for a set of questions, on average, only 55% of answers fell within their stated ranges.
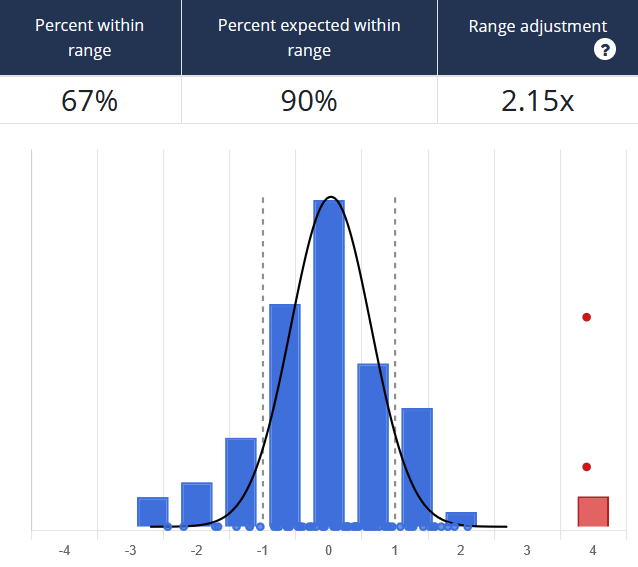
An example from our Calibration Training shows a group only getting 67% of questions within their stated ranges. Here the estimators’ lower and upper bound responses are normalized as values between -1 and 1. If the correct answer is outside their range, it falls above or below -1 and 1 on the graph. The red dots represent outliers where the response wasn’t just wrong but considerably far off.

 So how does AI stack up against humans here? In order to compare the performance of AI relative to human estimators, we asked 18 instances of ChatGPT 4 to provide 90% confidence interval estimates for a set of 20 questions on topics of sports, economics, and other metrics that are easily verifiable. This resulted in a total of 360 unique estimates. This differed from the trivia questions we use when calibrating human experts as ChatGPT 4 has access to all that information. Remember, the goal of calibration is not to answer questions correctly but to accurately reflect one’s own uncertainty. Trivia questions are used in our training because immediate feedback can be provided to individuals, which is essential in improving performance. To replicate this effect with AI, we limited the questions to ones that had actual answers manifest sometime between September 2021 (the data cutoff point for ChatGPT) and August 2023. An example of such a question is “How much will the top-grossing film earn internationally at the box office in 2022?”. This way we could evaluate whether the actual value (when analyzed retrospectively) fell within the estimated bounds by ChatGPT 4.
So how does AI stack up against humans here? In order to compare the performance of AI relative to human estimators, we asked 18 instances of ChatGPT 4 to provide 90% confidence interval estimates for a set of 20 questions on topics of sports, economics, and other metrics that are easily verifiable. This resulted in a total of 360 unique estimates. This differed from the trivia questions we use when calibrating human experts as ChatGPT 4 has access to all that information. Remember, the goal of calibration is not to answer questions correctly but to accurately reflect one’s own uncertainty. Trivia questions are used in our training because immediate feedback can be provided to individuals, which is essential in improving performance. To replicate this effect with AI, we limited the questions to ones that had actual answers manifest sometime between September 2021 (the data cutoff point for ChatGPT) and August 2023. An example of such a question is “How much will the top-grossing film earn internationally at the box office in 2022?”. This way we could evaluate whether the actual value (when analyzed retrospectively) fell within the estimated bounds by ChatGPT 4.
The results indicated below show the average calibration of the ChatGPT instance to be 60.28%, well below the 90% level to be considered calibrated. Interestingly, this is just slightly better than the average for humans. If ranked amongst humans, ChatGPT 4’s performance would rank at the 60th percentile from our sample.
If we applied this average level of human overconfidence toward hypothetical real-world cases, we would drastically underestimate the likelihood of extreme scenarios. For example, if a cybersecurity expert estimated financial losses to be between $10 – $50 million when a data breach occurs, they are stating there is only a 5% chance of losing more than $50 million. However, if they are as overconfident as the average human, the actual probability would be closer to 22.5%.
As far as humans go, there is some good news. Being accurately calibrated is not some innate talent determined by genetics, but a skill that can be taught and improved upon. Papers and studies provide conclusive evidence that humans can greatly improve their ability to give probabilistic estimates. HDR built upon these studies and developed online training that is specifically designed to improve individual human calibration for probabilistic estimates. Before training the average calibration level was 55% when trying to provide a 90% confidence interval for an uncertain quantity. By the end of training, this improved to 85%. Humans were able to better understand their own uncertainty and translate it into useful quantitative terms.
As we begin to rely more on language models, it is essential that we understand the uncertainty in the output they produce. In a follow-up and more in-depth study, HDR will be testing to see whether we can train ChatGPT and other language models to assess probabilistic estimates more accurately, and not fall victim to overconfidence or as Twain might put it “thinking what we know for sure that just ain’t so.”
Find out more about our state-of-the-art Calibration Training here
