
Understanding Research Credibility: HDR Analysts Contribute to SCORE
In working with clients at HDR, we are often faced with the question of how much confidence should be placed in a model result or empirical finding. Decision-making happens under uncertainty, so part of the job is deciding not just what the evidence says, but how much weight it should carry. That broader question is one reason why the results of the SCORE project are relevant to our current work.
SCORE was a DARPA-funded multi-method collaboration involving 865 researchers. As part of the initiative, the credibility of published findings was evaluated across three dimensions: reproducibility, robustness, and replicability.
- Researchers for the reproducibility study (Nature | Open Access) examined whether re-running an original analysis on the original data from published research articles will produce the same result reported by the original authors. Only approximately 54% of sampled papers were precisely reproducible. Papers from political science and economics journals had higher reproducibility rates compared to those from other disciplines. Paper recency and journal data sharing policies also predicted reproducibility.
- Researchers for robustness study (Nature | Open Access) tested whether conclusions hold when reasonable alternative analytical choices are applied to the same data. While 74% of the re-analyses reached the same conclusion as the original authors, quantitative results like effect sizes varied substantially.
- Researchers for the replicability study (Nature | Open Access) attempted independent replications of 274 claims drawn from 164 published papers. The replications were carefully designed, used the original materials when possible, and were peer-reviewed in advance. Only Fifty-five percent of claims replicated with statistically significant results in the original direction (see Figure 1). Replication rates varied somewhat across discipline and replication criteria.

These investigations remind us that research credibility is not a single property. A finding can survive one test and fail another. Reproducing an analysis, obtaining similar conclusions under alternative specifications, and observing the same result in new data each tell us something different. When the same findings are repeatedly observed, confidence in the robustness and reliability of the results increases. In fact, replication rates are essential for estimating the probability of a hypothesis being true (see Doug’s paper in the American Statistician for more on this point).
Confidence about research findings has value beyond the academic community. In applied work, we rely on leveraging empirical research to support our claims. Many HDR projects involve integrating multiple forms of evidence, each with different strengths and limitations. Historical observations, expert judgment, and external benchmarks may all serve as inputs into a model. Methods rooted in probabilistic reasoning and uncertainty quantification provide a framework for combining these sources while making confidence levels explicit. Rather than treating evidence as simply true or false, such approaches recognize that confidence should increase as findings remain consistent across multiple lines of inquiry and decrease when conclusions depend heavily on particular assumptions or analytical choices.
SCORE’s datasets, methods, and findings are openly available. Take a look! This initiative represents one of the most comprehensive efforts to quantify reliability in published social and behavioral science, and Peter and I are proud to have played a small part in it.







")


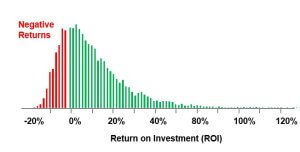 cash flow statement, and generating thousands of simulations. Using our Excel-based risk-return analysis (RRA) template, this process can take anywhere from 30 minutes to 6 hours, depending on the complexity of the problem and my familiarity with the topic.
cash flow statement, and generating thousands of simulations. Using our Excel-based risk-return analysis (RRA) template, this process can take anywhere from 30 minutes to 6 hours, depending on the complexity of the problem and my familiarity with the topic.















