There is good reason to believe that the number of the 2019 novel coronavirus- or 2019-nCoV – infections worldwide may be much greater than what has been reported so far. As of Tuesday, February 3, 2020, at 8:00am CST (UTC-6) the Johns Hopkins coronavirus tracking map shows there are 17,489 confirmed inflections. Of course, even in the best reporting systems, augmented with the fastest diagnoses, any number of reported infections would almost certainly be too low. However, our analysis points to a number of infections that may be in the hundreds of thousands, or possibly over one million – far above the latest official numbers.
Many informative analyses already exist on this outbreak, and it was relatively easy to build a model that accurately predicts the next few days of deaths and reported infections (Figure 1).
Figure 1: Prediction made on 1/25/2020 using a naïve exponential growth (daily) of 0.26 and a probability distribution function for time to death based off initial data. (http://www.nhc.gov.cn/yjb/s3578/202001/5d19a4f6d3154b9fae328918ed2e3c8a.shtml).
There is much more uncertainty regarding the total number of cases and infections. This number is crucial because it can inform the international community in terms of expected cases. The number of expected cases then informs decision-making and resource allocation from governments and non-governmental organizations (NGOs) to combat the spread. Too much uncertainty in either direction – overestimating versus underestimating – can result in efforts that are inefficient at best and ineffective or even harmful at worst.
While articles already exist that put the number of total cases at 75,000, we believe there is still a crucial distinction that hasn’t been incorporated: the incubation time and exponential growth of the virus, which can make the infections an order of magnitude higher than the symptomatic cases.
If the calculations in this article are correct, then there are already dozens of cases of 2019-nCoV in the United States, many of which will go undetected.
We support these assertions using two different methods of calculation, both of which depend, in part, on the fact that the average time to death from infection is long (25 days or greater on average, based on initial data). These calculations also depend on the observations that the average time from becoming infected to going to the hospital is 10-15 days; that only 20% of those infected ever require hospitalization; and that average time from hospitalization to death is relatively long (12 to 18 days).
Based on these calculations, we encourage world citizens and governments to all act now to prepare for a world-wide pandemic.
We begin by stating the summary of concerns:
2019-nCoV is not like the seasonal flu – it is more contagious, has a longer incubation period, has a much higher rate of serious complications (ICU bed requirement), and is deadlier, with a fatality rate that is five to 30 times higher.
Curious patterns in the data indicate the possibility of massive underreporting. a. This could partly due to the characteristics of the disease itself – a long incubation period and significant period of time from initial symptoms to the development of more serious symptoms. b. It could also be due in part to human systems for detecting the disease. Even assuming competence and best intentions, there are factors that will contribute to under-reporting in the early parts of an epidemic and during the period of exponential growth.
We remain impartial regarding whether China is intentionally misrepresenting data. Regardless, social media videos out of China on 1/23/2020 appear to indicate a gap between what was reported and what was actually occurring on the ground in the Wuhan province. Keep in mind that at the time China had reported only 21 deaths, while Wuhan was treating coronavirus in 20+ hospitals. While the baseline for hospitals in China may be more chaotic then Europe or the US, the videos do not appear to be consistent with something less impactful than the seasonal flu. Here is a scene from one of those Wuhan hospitals on 1/23/2020.
The Importance of Symptomatic Vs. Infected
As we mentioned, organizations across the globe are rushing to provide analysis and understanding. What we haven’t seen yet in any analysis, however, is a sobering realization: that the length of time from infection to death implies a number of infections that is two orders of magnitude higher than the current reports.
The lengthy incubation period represents a lag between the time someone becomes infected by the virus and when they begin to show symptoms. The incubation period for the common cold is anywhere from 24 to 72 hours; for the garden-variety flu, it’s two days on average. The incubation period for the Spanish flu, the deadliest pandemic in the history of the world after the Black Death, had an incubation period of two to seven days.
2019-nCoV, by contrast, has an incubation period that lasts an average of five to 10 days.
Incubation periods matter because the longer infected persons go without showing symptoms, the longer they go without seeking care and the more people they expose to the pathogens they carry inside of them. Calculating the number of people who have shown symptoms of 2019-nCoV, then, carries the risk of grossly undercounting the number of people who are actually infected.
A compelling picture of this issue is illustrated by comparing the number of infections and the number of symptomatic cases (Figures 2-4).
Figure 2: Monte Carlo Simulation results illustrating difference between infected and symptomatic cases (log scale).
Below we include individual histograms for both infections and symptomatic cases that illustrate the difference between reported cases, calculations based on current international symptomatic cases, and our calculations based on a Monte Carlo model that incorporates the incubation period. Note the scale on infections (Figure 4) is 10-15 times larger than the scale on symptomatic cases (Figure 3).
Figure 3: Symptomatic Cases of 2019-nCoV in Wuhan on Jan 23rd (histogram of 10,000 trials of a Monte Carlo model).
Figure 4: Infections of 2019-nCoV in Wuhan on Jan 23rd (histogram of 10,000 trials of a Monte Carlo model).
Even Thursday’s Lancet paper, which is backing out 75,000 Wuhan infections as of 1/25/2020 is low for the same reason – they are using international “infections” as their starting point and observing it is an unrealistic number given a mere 3,300 daily international passengers out of Wuhan before the quarantine. But the results are likely low because of the nature of growth and long incubation period of this virus – they can only count the “symptomatic” international cases – not the infected international cases.
How Lagging Indicators Obscure Reality
Sometimes, our understanding of the actual magnitude of an event, like a pandemic, is limited by the fact that even in the best of circumstances, data often lags behind the pace of reality.
Based on the published case history of the first 17 deaths occurring from 2019-nCoV, the average time from infection to death is 22-35 days (1-14 days for incubation, five days from onset of symptoms to hospitalization, and 12-18 days from hospitalization to death). In addition, only 20% of those infected ever require hospitalization.
We also have the epidemiological reality that time to death is always underrepresented during the exponential growth phase of an epidemic because the people who take a long time to die haven’t died yet.
The implications of this long time from infection to death makes it difficult for the public to comprehend, during the early stages, the stunning nature of the implied exponential growth in cases.
Put another way, the situation could very well be worse than we believe because we expect the numbers we receive in the news to be closer to the truth than what they really are: a snapshot of the past that grows older and more obsolete at a dizzying pace.
To be conservative, let us assume that the average time to death from infection is 25 days (the Monte Carlo simulations with the best fit to deaths is 29 days from infection to death). This implies that, given a 2.5% fatality rate, and that 362 people have died, there were 14,480 cases 25 days ago. Stated otherwise, given that it takes 25 days to die from infection, 14,480 were infected as of 1/9/2020! (At the time, the official number of confirmed cases was just 41.)
Combine this with a fearsome exponential growth from 1/9/2020 until the quarantine on 1/23/2020 and one starts to get the picture.
Shedding Light on Exponential Growth Rates with Probabilistic Models: How Many People Are Really Infected?
We still can’t make a definitive estimate of exponential growth, in part, because it changes over time as behaviors change. However, the beauty of a probabilistic model, one using initially wide ranges for variables, is that we can quickly discern certain values of variables that are unrealistic. In other words, the model can rapidly narrow the wide amount of uncertainty we have about a given variable (i.e. infection rates).
Using this method, we have concluded that the unrestrained (i.e., before quarantine) log growth rate of 2019-nCoV is at least 0.26 and as high as 0.31. This implies a doubling time in the initial stages of the outbreak of between 2.3 and 2.7 days – far less than other published estimates. A shorter doubling time represents the virus spreading faster among a given population. When coupled with the other observations the international community has gathered about the virus, the models give us a range of likely outcomes that reduce the uncertainty to as much as possible given what we know now.
The results are disquieting. Our best estimates for current infections are 800,000 in Hubei/Wuhan and 337,000 in the rest of China (Table 1).
Table 1: Monte Carlo predictions for current levels of 2019-nCoV in Hubei, China ex Hubei, and International.
How Could This Be?
Skeptics at this point will say, “How could 1,000,000 people in Wuhan be sick? That would imply that every 8th person was sick and that would be all over the media!”
First, there has been very little reporting out of Wuhan in the last week. Governments at all levels have moved to restrict access into and out of the quarantine zone, leaving first-hand news via uncontrolled sources in scant supply.
Second, there is a big difference between 1,000,000 infected and 1,000,000 sick. Because the incubation period is so long, even if 1,000,000 were infected, only a few hundred thousand might be symptomatic.
Skeptics might still say, “How could even 300,000 be sick when the official number is only 11,000?” Recall that the average time from becoming symptomatic to going to the hospital is five days, and that only 20% ever require hospitalization. That means only 60,000 of those 300,000 will require hospitalization. Add in the average lag between being symptomatic and hospitalization, and physical limitations at hospitals, and 11,000 is a very reasonable number of reported cases.
Therefore, it is entirely believable that 1,000,000 people are infected with 2019-nCoV as of 2/3/2020, and with 500,000 infections realized before the time the quarantine was in place on 1/23/2020.
If this is true, then at least 200 infected people flew to international destinations before the quarantine, and 75,000 infected people traveled to domestic Chinese destinations before the quarantine. Given the exponential rate of growth discussed previously, it is possible – perhaps likely – that the original Wuhan quarantine was too little, too late to keep the pandemic from spreading.
Implications for Mainland China
The bad news is that given there are likely hundreds of thousands of infections in China, it is unlikely that China will be “open for business” in the next month – possibly even the next several months. Undoubtedly, the unprecedented quarantine and public health measures China has taken will have reduced the log growth rate of new cases. However, because of the long incubation time and the uncertainty around reporting, we will have wide error bars around our estimate of the new rate of growth for several weeks.
Implications for Other Countries
Given how contagious the disease is, and the continued free flow of international travel from other Chinese ports up through 2/1/2010, an international pandemic likely at this point.
However, there is reason to be encouraged by the international response thus far. The numbers of reported and predicted infections are relatively low, and many people with the virus have largely self-quarantined, which helps tremendously.
The biggest issue is that our sample of infected people is going to be skewed toward the responsible people. Responsible actors will appear in reports; less responsible actors may not. People who have visited China in January and don’t self-quarantine, or who display very moderate symptoms, could slip through the cracks. There is already evidence that infected people with few symptoms can infect clusters of people. The possibility for an epidemic in another country comes if these clusters aren’t immediately caught.
How might this happen? Here is an actual story that has already been reported. An older couple from Wuhan visited their daughter in Shanghai some time during the week before 1/15/2020. They were infected with 2019-nCoV; the daughter soon caught it as well. The daughter then flew to Germany on the 15th and spent a week with colleagues before returning to Shanghai on 1/22/2020. She only became symptomatic after leaving Germany, but had infected several Germans before doing so.
What Do I Do?
Hope is not a good strategy to mitigate risk. While positive interpretations of the data exist, counting on that to be reality sets us up to repeat the initial mistakes in early January to contain and mitigate the virus.
Most humans don’t like to think about things like this because cold, uncompromising reality is uncomfortable, forcing us to decide to either change our habits or face the possibility of disease or death. Nevertheless, making rational decisions to protect yourself based on a sound statistical and logical analysis has helped many millions of lives in the course of human history.
Our recommendation is that we directly address the issue that the current and eventual spread and magnitude of the outbreak could be worse than we believe or imagine, bearing in mind that it is possible we may only have a few days before outbreaks start popping up in the U.S. and possibly just weeks before a general epidemic begins stateside.
Part of the resistance to thinking about pandemics is that it is easy (but incorrect) to assume that we are powerless to affect the outcome. Here are three easy things we can do on a personal level:
Wash our hands. This isn’t as easy as it sounds – it means creating a new habit where we wash or disinfect our hands whenever we’ve contacted a public surface (grocery cart, bathroom door handle, etc.). Disinfecting helps. Washing and scrubbing with soap for 15 seconds is the formal protocol.
Some published research shows that elderberry syrup may reduce the severity of other types of flu viruses and reduce the probability of transmission.
If there is a cluster or outbreak in your city, minimize or avoid public gatherings and wear protective facemasks in public. This is probably the most difficult one because it comes at a high social cost some people aren’t willing to pay.
Preparations for Your Business
If you’d like help preparing your business for the possibilities, there are certain practices you can adopt now that will give you an advantage regardless of outcome (such as reviewing your capabilities for remote work). Also, if you’d like to use or test scenarios on the Monte Carlo model we created, please contact us. One of the advantages of using a probabilistic model is that you can update the uncertainty in real time and always know what contingencies you need to put in place for the most likely scenarios.
Matt Millar is a senior quantitative analyst with Hubbard Decision Research. Contact Matt for more information on this article or any of the methods discussed wherein.
RECOMMENDED READING:
TROJAN HORSE: HOW A PHENOMENON CALLED MEASUREMENT INVERSION CAN MASSIVELY COST YOUR COMPANY
Measuring the wrong variables is a Trojan horse that infiltrates virtually every organization. This phenomenon has a real cost that can be measured – and avoided.
TWO WAYS YOU CAN USE SMALL SAMPLE SIZES TO MEASURE ANYTHING
A measurement isn’t useless if the sample size is small. You can actually use small sample sizes to learn something useful about anything – and use that insight to make better decisions.
Any decision can be made better through better measurements – and as these three examples show, just five data points can tip the scales in a business decision.
A Trojan horse is anything that introduces risk to an organization through something that appears to be positive
Measuring the wrong variables is a Trojan horse that infiltrates virtually every organization
This phenomenon has a real cost that can be measured – and avoided
The Trojans stood at the walls, drunk from victory celebrations after they had previously watched the Greek fleets set sail away in retreat, having been defeated after nearly 10 years of constant warfare. They had little reason to suspect treachery when they saw the massive wooden horse just outside their gates, apparently a gift offering from the defeated Greeks. Because of their confidence – or overconfidence – they opened the gates and claimed the wooden horse as the spoils of war.
Later that night, after the Trojans lay in drunken stupor throughout the city, a force of Greek soldiers hidden in the horse emerged and opened the gates to the Greek army that had not retreated but had actually lay in wait just beyond sight of the city. Swords drawn and spears hefted, the Greek soldiers spread throughout the city and descended upon its people.
The end result is something any reader of The Illiad knows well: the inhabitants of Troy were slaughtered or sold into slavery, the city was razed to the ground, and the term “Trojan horse” became notorious for something deceitful and dangerous hiding as something innocuous and good.
Organizations are wising up to the fact that quantitative analysis is a vital part of making better decisions. Quantitative analysis can even seem like a gift, and used properly, it can be. However, the act of measuring and analyzing something can, in and of itself, introduce error – something Doug Hubbard calls the analysis placebo. Put another way, merely quantifying a concept and subjecting the data to an analytical process doesn’t mean you’re going to get better insights.
It’s not just what data you use, although that’s important. It’s not even how you make the measurements, which is also important. The easiest way to introduce error into your process is to measure the wrong things – and if you do, you’re bringing a Trojan horse into your decision-making.
Put another way, the problem is an insidious one: what you’re measuring may not matter at all, and may just be luring you into a false sense of security based on erroneous conclusions.
The One Phenomenon Every Quantitative Analyst Should Fear
Over the past 20 years and throughout over 100 measurement projects, we’ve found a peculiar and pervasive phenomenon: that what organizations tend to measure the most often matters the least – and what they aren’t measuring tends to matter the most. This phenomenon is what we call measurement inversion, and it’s best demonstrated by the following image of a typical large software development project (Figure 1):
Figure 1: Measurement Inversion
Some examples of measurement inversion we’ve discovered are shown below (Figure 2):
Figure 2: Real Examples of Measurement Inversion
There are many reasons for measurement inversion, ranging from the innate inconsistency and overconfidence in subjective human assessment to organizational inertia where we measure what we’ve always measured, or what “best practices” say we should measure. Regardless of the reason, every decision-maker should know one, vital reality: measurement inversion can be incredibly costly.
Calculating the Cost of Measurement Inversion for Your Company
The Trojan horse cost Troy everything. That probably won’t be the case for your organization, as far as one measurement goes. But there is a cost to introducing error into your analysis process, and that cost can be calculated like anything else.
We uncover the value of each piece of information with a process appropriately named Value of Information Analysis (VIA). VIA is based on the simple yet profound premise that each thing we decide to measure comes with a cost and an expected value, just like the decisions these measurements are intended to inform. Put another way, as Doug says in How to Measure Anything, “Knowing the value of the measurement affects how we might measure something or even whether we need to measure it at all.” VIA is designed to determine this value, with the theory that choosing higher-value measurements should lead to higher-value decisions.
Over time, Doug has uncovered some surprising revelations using this method:
Most of the variables used in a typical model have an information value of zero
The variables with the highest information value were usually never measured
The most measured variables had low to no value.
The lower the information value of your variables, the less value you’ll generate from your model. But how does this translate into costs?
A model can calculate what we call your Overall Expected Opportunity Loss (EOL), or the average of each expected outcome that could happen as a result of your current decision, without measuring any further. We want to get the EOL as close to zero as possible. Each decision we make can either grow the EOL or shrink it. And each variable we measure can influence those decisions. Ergo, what we measure impacts our expected loss, for better or for worse.
If the variables you’re measuring have a low information value – or an information value of zero – you’ll waste resources measuring them and do little to nothing to reduce your EOL. The cost of error, then, is the difference between your EOL with these low-value variables and the EOL with more-valuable variables.
Case in point: Doug performed a VIA for an organization called CGIAR. You can read the full case study in How to Measure Anything, but the gist of the experience is this: by measuring the right variables, the model was able to reduce the EOL for a specific decision – in this case, a water management system – from $24 million to under $4 million. That’s a reduction of 85%.
Put another way, if they had measured the wrong variables, then they would’ve incurred a possible cost of $20 million, or 85% of the value of the decision.
The bottom line is simple. Measurement inversion comes with a real cost for your business, one that can be calculated. This raises important questions that every decision-maker needs to answer for every decision:
Are we measuring the right things?
How do we know if we are?
What is the cost if we aren’t?
If you can answer these questions, and get on the right path toward better quantitative analysis, you can be more like the victorious Greeks – and less like the citizens of a city that no longer exists, all because what they thought was a gift was the terrible vehicle of their destruction.
Learn how to start measuring variables the right way – and create better outcomes – with our hybrid learning course, How To Measure Anything: Principles of Applied Information Economics.
The most common reason organizations fail at innovating might not be what you think
Defining what innovation means to an organization is critical for success
Even the best-defined innovation initiatives fail if they aren’t properly measured
Innovation has captured the imagination of business leaders everywhere. Everyone wants to create that ground-breaking, disruptive product or service that turns the industry on its head. Or, at the very least, they want to move toward changing anything – paradigms, processes, markets, you name it – that will take the organization to that next level.
Unfortunately, many innovation initiatives fail, a failure being an outcome which is disproportionately smaller than expectations, allocated resources, or both. They happen quite commonly, and business literature is rife with reasons why, ranging from not having ideas that are “good” to not having the right people, enough budget, or an accepting culture.
The main reason an innovation initiative fails, however, is more fundamental: companies aren’t doing a good enough job defining what innovation actually means and then measuring it.
The Innovation Definition Problem
Decision-makers that this very moment are spending a staggeringly-high percentage of their revenue trying to innovate often don’t have a firm definition of what innovation means – and this isn’t just academic.
Innovation is a vague, mostly meaningless term that obscures what you’re really trying to accomplish. It can mean almost anything. Everyone has a definition; here’s 15 of them.
What we’ve found when faced with these terms (and there are a lot of them) is that either the decision-makers know what they want to accomplish, but they don’t know how to measure it, or they think they know what they want to accomplish, but they’re measuring the wrong things (or even pursuing the wrong goal).
So, how do you define the problem? When organizations want to innovate, they’re largely looking to do something that they couldn’t previously do, for the purpose of taking the company to a level it couldn’t previously reach.
How they achieve this is largely a function of two things: impact and timeliness. The earlier a company undertakes an initiative, and the more impact that initiative has, the more innovative a company will be, as shown by the Innovation Time/Impact Square in figure 1:
Figure 1 – Innovation Time/Impact Square
In our experience, the companies that find the greatest success compared to their peers come up with better ideas – impact – and do so usually before anyone else – timeliness. If your products or services are producing a lot of return, but you are behind the curve, you’re mainly just catching up by implementing best practices. If you’re getting there first, but your concepts aren’t particularly high-value, then you’re underachieving given your abilities. And if your concepts are low value and based only on what others have done before you, you’re falling behind.
Any of the three states of being may be acceptable, but none are examples of innovation.
What does “impact” mean? One way to define it is to select an objective – revenue growth, higher stock price, more sales, greater market share, or some other desired outcome – and determine the growth target.
Of course, no organization is going to spend a significant portion of their budget on merely adding a percent or two to their growth, not if they can help it. The allure of innovation is substantial, paradigm-changing growth.
What that growth looks like specifically depends on the firm, but the reality is simple: spending significant resources on innovation – a difficult and costly process – needs to be worth it.
“Timeliness” can mean a variety of things as well. Increasing the quantity of product concepts produced over a given period of time is one definition. Identifying new trends before anyone else is another. Focusing on speeding up the pace at which you create does have value in and of itself, but investing too much in accomplishing this goal can result in lower overall return.
Framing innovation in this way gives you the basis to make better decisions on anything from how much to increase the R&D budget to who you need to hire, what technology you need to acquire, or what you need to do to improve the quality of the ideas your organization creates.
Once you’ve defined what innovation means to your organization, you then have to measure it.
The Innovation Measurement Problem
The innovation measurement problem is simple: companies, by and large, don’t know how to measure this concept. In practice, this means most firms can’t:
Evaluate how “good” they are at innovation, whatever that means
Figure out what it takes to get “better” at innovation, whatever that looks like
Determine the cost of doing those things to get “better” and forecasting ROI
The first major attempt to accomplish the first task came in 1976, when Michael Kirton produced a paper identifying the two types of creators: adaptors (those who make existing processes better) and innovators (those who do something different). From this effort came the Kirton Adaption-Innovation (KAI) Inventory, which basically provides a person with where he or she falls on this adaption-innovation continuum.
The effort is a noble one, but we don’t have any sense of objective value. Are people at the Innovation end of the scale better at growing a company than the ones at the other end, and if so, by how much?
These kinds of problems aren’t specific to just the KAI inventory; they’re found in almost every attempt to quantify the processes, impacts, and probability of innovation initiatives.
For example, some organizations also use what academics call semi-quantitative measures (we call them pseudo-quantitative ones) like the “innovation Balanced Scorecard” promoted in 2015, and the “Innovation Audit Scorecard,” promoted in 2005. The flaws of these particular methods are explained in How to Measure Anything; they include the following:
Ranges of values on scorecards are largely arbitrary;
Weighting scores is also arbitrary (i.e. how do you know this component, weighted at 15%, is twice as important as one weighted 7.5% Are those individual values accurate?);
Estimates are usually subjective and uncalibrated, even from experts;
It’s impossible to perform meaningful mathematical operations with ordinal scales (i.e. is something that is a 4 really twice as effective as something that’s a 2?)
They don’t incorporate probabilities of outcomes; and
Using one gives you the illusion of improving decision-making, even though doing so may actually introduce error (a concept called the analysis placebo)
McKinsey, to its credit, promotes two quantitative metrics to evaluate effectiveness of R&D expenditures (ratio of R&D spending to new product sales and product-to-margin conversion rate), but even this approach doesn’t speak to whether or not the innovation problem lies within R&D – or if focusing on improving these two metrics is the best action to take.
Plus, R&D is only one way a company can innovate, per how we defined the concept above, and it doesn’t exist in a vacuum; it is accompanied by a host of other factors and strategies.
There’s a bigger problem, though, with measuring innovation: even if you come up with “good” metrics, no one tells you which “good” metrics have the most predictive power for your organization. In other words, each variable, each measurement, each bit of information you gather has a certain value. The vast majority of the time, organizations have no idea what the value of these pieces of information are – which leads to them measuring what is easy and simple and intuitive rather than what should be measured.
For example, one common metric that is bandied about is the number of patents created in a certain period of time (i.e. a quarter, or a year). Refer back to the Innovation Time/Impact Square above. More patents increase the chance that you’ll get there first, right? Maybe – but that may not make you more innovative. What if you modeled your creative process and actually estimated the market potential of an idea before you developed and patented it and found that your ideas, as it turns out, have consistently low market potential? Then your problem isn’t “How do we create more ideas?”; it’s “How do we create better ideas?”
It doesn’t matter if you know you need to create ideas that are more timely and more impactful if you can’t measure either. You won’t be able to make the best decisions, which will keep your organization out of the rarified air of the innovators.
The bottom line: focusing on defining innovation for your firm and creating better measurements based on those definitions is the only proven way to improve innovation.
Learn how to start measuring innovation the right way – and create better outcomes – with our two-hour How to Measure Anything in Innovation webinar. $150 – limited seating.
A powerful quantitative analysis method was created as a result of the Manhattan Project and named for an exotic casino popularized by the James Bond series
The tool is the most practical and efficient way of simulating thousands of scenarios and calculating the most likely outcomes
Unlike other methods, this tool incorporates randomness that is found in real-world decisions
Using this method doesn’t require sophisticated software or advanced training; any organization can learn how to use it
A nuclear physicist, a dashing British spy, and a quantitative analyst walk into a casino. This sounds like the opening of a bad joke, except what all of these people have in common can be used to create better decisions in any field by leveraging the power of probability.
The link in question – that common thread – gets its name from an exotic locale on the Mediterranean, or, specifically, a casino. James Bond visited a venue inspired by it in Casino Royale, a book written by Ian Fleming, who – before he was a best-selling author – served in the British Naval Intelligence Division in World War II. While Fleming was crafting creative plans to steal intel from Nazi Germany, a group of nuclear physicists on the other side of the Atlantic were crafting plans of their own: to unleash the awesome destructive power of nuclear fission and create a war-ending bomb.
Trying to predict the most likely outcome during a theoretical nuclear fission reaction was difficult to say the least, particularly using analog computers. To over-simplify the challenge, scientists had to be able to calculate whether or not the bomb they were building would explode – a calculation that required an integral equation to somehow predict the behavior of atoms in a chain reaction. Mathematicians Stanislaw Ulam and John Von Nuemann, both members of the Manhattan Project, created a way to calculate and model the sum of thousands of variables (achieved by literally placing a small army of smart women in a room and having them run countless calculations). When they wanted to put a name to this method, Ulam recommended the name of the casino where his uncle routinely gambled away large sums of money<fn>Metropolis, N. (1987). The Beginning of the Monte Carlo Method. Los Alamos Science, 125-130. Retrieved from https://permalink.lanl.gov/object/tr?what=info:lanl-repo/lareport/LA-UR-88-9067</fn>.
That casino – the one Fleming’s James Bond would popularize and the one where Ulam’s uncle’s gambling addiction took hold – was in Monte Carlo, and thus the Monte Carlo simulation was born.
Now, the Monte Carlo simulation is one of the most powerful tools a quantitative analyst can use when incorporating the power of probabilistic thinking into decision models.
How a Monte Carlo Simulation Works – and Why We Need It To
In making decisions – from how to make a fission bomb to figuring out a wager in a table game in a casino – uncertainty abounds. Uncertainty abounds because, put simply, a lot of different things can happen. There can be almost-countless scenarios for each decision, and the more variables and measurements are involved, the more complicated the calculations become to try and figure out what’s most likely to happen.
If you can reduce possible outcomes to a range of probabilities, you can make better decisions in theory. The problem is, doing so is very difficult without the right tools. The Monte Carlo simulation was designed to address that problem and provide a way to calculate the probability of thousands of potential outcomes through sheer brute force.
Doug Hubbard provides a scenario in The Failure of Risk Management that explains how a Monte Carlo simulation works and can be applied to a business case (in this context, figuring out the ROI of a new piece of equipment). Assume that you’re a manager considering the potential value of a new widget-making machine. You perform a basic cost-benefit analysis and estimate that the new machine will make one million widgets, delivering $2 of profit per unit. The machine can make up to 1.25 million, but you’re being conservative and think it’ll operate at 80% capacity on average. We don’t know the exact amount of demand. We could be off by as much as 750,000 widgets per year, above or below.
We can conceptualize the uncertainty we have like so:
Demand: 250,000 to 1.75 million widgets per year
Profit per widget: $1.50 to $2.50
We’ll say these numbers fall into a 90% confidence interval with a normal distribution. There are a lot of possible outcomes, to put it mildly (and this is a pretty simple business case). Which are the most likely? In the book, Doug used an MC simulation to run 10,000 simulations – or 10,000 scenarios – and tallied the results for each (with each scenario representing some combination of demand and profit per widget to create a loss or gain). The results are described by two figures: a histogram of outcomes (figure 1) and a cumulative probability chart (figure 2)<fn>Hubbard, D. W. (2009). The failure of risk management: Why its broken and how to fix it. Hoboken, NJ: J. Wiley & Sons.</fn>:
Figure 1: Histogram of Outcomes
Figure 2: Cumulative Probability Chart
You, the manager, would ideally then calculate your risk tolerance and use this data to create a loss exceedance curve, but that’s another story for another day. As Doug explains, using the MC simulation allowed you to gain critical insight that otherwise would’ve been difficult to impossible to obtain:
Without this simulation, it would have been very difficult for anyone other than mathematical savants to assess the risk in probabilistic terms. Imagine how difficult it would be in a more realistically complex situation.
The best way to sum up the diverse benefits of incorporating MC simulations into decision models was written by a group of researchers in an article titled “Why the Monte Carlo method is so important today”:<fn>Kroese DP, Brereton T, Taimre T, Botev ZI. Why the Monte Carlo method is so important today. Wiley Interdisciplinary Reviews: Computational Statistics2014; 6( 6): 386– 392.</fn>
Easy and Efficient. Monte Carlo algorithms tend to be simple, flexible, and scalable.
Randomness as a Strength. The inherent randomness of the MCM is not only essential for the simulation of real-life random systems, it is also of great benefit for deterministic numerical computation.
Insight into Randomness. The MCM has great didactic value as a vehicle for exploring and understanding the behavior of random systems and data. Indeed we feel that an essential ingredient for properly understanding probability and statistics is to actually carry out random experiments on a computer and observe the outcomes of these experiments — that is, to use Monte Carlo simulation.
Theoretical Justification. There is a vast (and rapidly growing) body of mathematical and statistical knowledge underpinning Monte Carlo techniques, allowing, for example, precise statements on the accuracy of a given Monte Carlo estimator (for example, square-root convergence) or the efficiency of Monte Carlo algorithms.
Summarized, Monte Carlo simulations are easy to use, not only help you more closely replicate real-life randomness but understand randomness itself, and are backed by scientific research and evidence as to how they make decision models more accurate. We need them to work because any significant real-world decision comes with a staggering amount of uncertainty, complicated by thousands of potential outcomes created by myriad combinations of variables and distributions – all with an eminently-frustrating amount of randomness haphazardly mixed throughout.
How to Best Use a Monte Carlo Simulation
Of course, knowing that an MC simulation tool is important – even necessary – is one thing. Putting it into practice is another.
The bad news is that merely using the tool doesn’t insulate you from a veritable rogue’s gallery of factors that lead to bad decisions, ranging from overconfidence to using uncalibrated subjective estimates, falling victim to logical fallacies, and making use of soft-scoring methods, risk matrices, and other pseudo-quantitative methods that aren’t better than chance and frequently worse.
The good news is that all of those barriers to better decisions can be overcome. Another piece of good news: you don’t need sophisticated software to run a Monte Carlo simulation. You don’t even need specialized training. Many of the clients we train in our quantitative methodology don’t have either. You can actually build a functional MC simulation in native Microsoft Excel. Even a basic version can help by giving you more insight than you know now; by giving you another proven way to glean actionable knowledge from your data.
On its own, though, a MC simulation isn’t enough. The best use of the Monte Carlo method is to incorporate it into a decision model. The best decision models employ proven quantitative methods – including but not limited to Monte Carlo simulations – to follow the process below (figure 3):
Figure 3: HDR Decision Analysis Process
The outputs of a Monte Carlo simulation are typically shown in that last step, when the model’s outputs can be used to “determine optimal choice,” or, figure out the best thing to do. And again, you don’t need specialized software to produce a working decision model; Microsoft Excel is all you need.
You may not be creating a fearsome weapon, or out-scheming villains at the baccarat table, but your decisions are important enough to make using the best scientific methods available. Incorporate simulations into your model and you’ll make better decisions than you did before – decisions a nuclear physicist or a secret agent would admire.
Recommended Products:
Learn how to create Monte Carlo simulations in Excel with our Basic Simulations in Excel webinar. Register today to get 15% off with coupon code EXCEL15.
Fears of a recession are rising as experts attempt to predict when a recession will officially occur
Forecasting a recession, for most practical purposes, is irrelevant to decision-makers
Decision-makers need to ask the right questions that will help them mitigate the risk a recession poses
A Google search of “risk of recession” uncovers a treasure trove of prognostication, hand-wringing, and dire predictions – or sneering dismissals – involving whether or not the U.S. economy will soon take a nosedive.
It’s surely a worrisome time. Even though the economy appears to be going strong – unemployment is still low, credit spreads are stable, etc. – there’s a tremendous amount of uncertainty when it comes to what the economy will do. If we knew when the recession would hit, we’d be able to do something about it, although “do something” is vague and means different things for different people and, frankly, we as a nation aren’t particularly good at knowing what that “something” is, let alone doing it.
Throw in the fact that the formal announcement of a recession always lags when the recession actually began, and our need to be able to predict the expected downturn only grows.
But two things are very possible, maybe even probable:
The recession has already begun; and
Asking when the recession will happen is completely irrelevant.
It Doesn’t Matter If We’re In a Recession Right Now
If a time traveler came to you from ten years from now and told you that this day marked the official beginning of the Great Recession Part 2: Judgment Day (or whatever clever name economic historians will bestow on it), would it make a difference?
Probably not, because it would be too late to take actions to avoid the recession, since it’s already here.
But even if the time traveler instead said that the recession would start three months from now, or six months, or 12 months, would that make a difference? Possibly – but it’s also very possible that the economic risks that collectively cause and make up a “recession” have already started impacting your business.
And if you knew that the recession was six months down the road, maybe you put off taking the actions that you need to take today (or needed to take X months ago) in order to mitigate the damage your organization could incur.
No matter how you slice it, asking “When will we be in recession?” or “Are we already in a recession?” is not only mostly irrelevant, but also largely counterproductive because it takes our focus off what we should already be doing: asking the right questions.
Questions we should ask instead are:
What impact will a recession actually have on my organization?
What specific economic risks are most likely for me?
When would these risks start impacting my organization? Can I tell if they already have?
What can I do today to mitigate these risks as much as possible?
All of these questions are completely independent and not reliant on knowing when a recession will happen. Remember, what constitutes a recession is completely arbitrary. It’s also one broad term for dozens of individual risks that tend to happen in clusters during recession periods but may all begin or end at wildly different times, and have different severity.
Developing answers to the above questions is far more productive than trying to discern when the recession will happen by reading news articles, watching percentages go up and down on TV, or hiring shamans to study chicken entrails. If you can find those answers, you’ll be far ahead of the curve and increase your chances of being in the minority of organizations that not only weathers economic downturns, but actually grows during them.
Quantitative commercial real estate modeling is becoming more widespread, but is still limited in several crucial ways
You may be measuring variables unlikely to improve the decision while ignoring more critical variables
Some assessment methods can create more error than they remove
A sound quantitative model can significantly boost your investment ROI
Quantitative commercial real estate modeling (CRE), once the former province of only the high-end CRE firms on the coasts, has become more widespread – for good reason. CRE is all about making good decisions about investments, after all, and research has repeatedly shown how even a basic statistical algorithm outperforms human judgment<fn>Dawes, R. M., Faust, D., & Meehl, P. E. (n.d.). Statistical Prediction versus Clinical Prediction: Improving What Works. Retrieved from http://meehl.umn.edu/sites/g/files/pua1696/f/155dfm1993_0.pdf</fn><fn>N. Nohria, W. Joyce, and B. Roberson, “What Really Works,” Harvard Business Review, July 2003</fn>.
Statistical modeling in CRE, though, is still limited, for a few different reasons, which we’ll cover below. Many of these limitations actually result in more error (one common misconception is merely having a model improves accuracy, but sadly that’s not the case). Even a few percentage points of error can result in significant losses. Any investor that has suffered from a bad investment knows all too well how that feels. So, through better quantitative modeling, we can decrease the chance of failure.
Here’s how to start.
The Usual Suspects: Common Variables Used Today
Variables are what you’re using to create probability estimates – and, really, any other estimate or calculation. If we can pick the right variables, and figure out the right way to measure them (more on that later), we can build a statistical model that has more accuracy and less error.
Most commercial real estate models – quantitative or otherwise – make use of the same general variables. The CCIM Institute, in its 1Q19 Commercial Real Estate Insights Report, discusses several, including:
Employment and job growth
Gross domestic product (GDP)
Small business activity
Stock market indexes
Government bond yields
Commodity prices
Small business sentiment and confidence
Capital spending
Data for these variables is readily available. For example, you can go to CalculatedRiskBlog.com and check out their Weekly Schedule for a list of all upcoming reports, like the Dallas Fed Survey of Manufacturing Activity, or the Durable Goods Orders report from the Census Bureau.
The problem, though, is twofold:
Not all measurements matter equally, and some don’t matter at all.
It’s difficult to gain a competitive advantage if you’re using the same data in the same way as everyone else.
Learning How to Measure What Matters in Commercial Real Estate
In How to Measure Anything: Finding the Value of Intangibles in Business, Doug Hubbard explains a key theme of the research and practical experience he and others have amassed over the decades: not everything you can measure matters.
When we say “matters,” we’re basically saying that the variable has predictive power. For example, check out Figure 1. These are cases where the variables our clients were initially measuring had little to no predictive power compared to the variables we found to be more predictive. This is called measurement inversion.
Figure 1: Real Examples of Measurement Inversion
The same principle applies in CRE. Why does measurement inversion exist? There are a few reasons: variables are often chosen based on intuition/conventional wisdom/experience, not statistical analysis or testing; decision-makers often assume that industries are more monolithic than they really are when it comes to data and trends (i.e. all businesses are sufficiently similar that broad data is good enough); intangibles that should be measured are viewed as “impossible” to measure; and/or looking into other, “non-traditional” variables comes with risk that some aren’t willing to take. (See Figure 2 below.)
Figure 2: Solving the Measurement Inversion Problem
The best way to begin overcoming measurement inversion is to get precise with what you’re trying to measure. Why, for example, do CRE investors want to know about employment? Because if too many people in a given market don’t have jobs, then that affects vacancy rates for multi-family units and, indirectly, vacancy rates for office space. That’s pretty straightforward.
So, when we’re talking about employment, we’re really trying to measure vacancy rates. Investors really want to know the likelihood that vacancy rates will increase or decrease over a given time period, and by how much. Employment trends can start you down that path, but by itself isn’t not enough. You need more predictive power.
Picking and defining variables is where a well-built CRE quantitative model really shines. You can use data to test variables and tease out not only their predictive power in isolation (through decomposition and regression), but also discover relationships with multi-variate analysis. Then, you can incorporate simulations and start determining probability.
For example, research has shown<fn>Heinig, S., Nanda, A., & Tsolacos, S. (2016). Which Sentiment Indicators Matter? An Analysis of the European Commercial Real Estate Market. ICMA Centre, University of Reading</fn> that “sentiment,” or the overall mood or feeling of investors in a market, isn’t something that should be readily dismissed just because it’s hard to measure in any meaningful way. Traditional ways to measure market sentiment can be dramatically improved by incorporating tools that we’ve used in the past, like Google Trends. (Here’s a tool we use to demonstrate a more predictive “nowcast” of employment using publicly-available Google Trend information.)
To illustrate this, consider the following. We were engaged by a CRE firm located in New York City to develop quantitative models to help them make better recommendations to their clients in a field that is full of complexity and uncertainty. Long story short, they wanted to know something every CRE firm wants to know: what variables matter the most, and how can we measure them?
We conducted research and gathered estimates from CRE professionals involving over 100 variables. By conducting value of information calculations and Monte Carlo simulations, along with using other methods, we came to a conclusion that surprised our client but naturally didn’t surprise us: many of the variables had very little predictive power – and some had far more predictive power than anyone thought.
One of the latter variables wound up reducing uncertainty in price by 46% for up to a year in advance, meaning the firm could more accurately predict price changes – giving them a serious competitive advantage.
Knowing what to measure and what data to gather can give you a competitive advantage as well. However, one common source of data – inputs from subject-matter experts, agents, and analysts – is fraught with error if you’re not careful. Unfortunately, most organizations aren’t.
How to Convert Your Professional Estimates From a Weakness to a Strength
The bottom line is that there are plenty of innate cognitive biases that even knowledgeable and experienced professionals fall victim to. These biases introduce potentially disastrous amounts of error that, when left uncorrected, can wreak havoc even with a sophisticated quantitative model. (In The Quants, Scott Patterson’s best-selling chronicle of quantitative wizards who helped engineer the 2008 collapse, the author explains how overly-optimistic, inaccurate, and at-times arrogant subjective estimates undermined the entire system – to disastrous results.)
The biggest threat is overconfidence, and unfortunately, the more experience a subject-matter expert has, the more overconfident he/she tends to be. It’s a catch-22 situation.
You need expert insight, though, so what do you do? First, understand that human judgments are like anything else: variables that need to be properly defined, measured, and incorporated into the model.
Second, these individuals need to be taught how to control for their innate biases and develop more accuracy with making probability assessments. In other words, they need to be calibrated.
Research has shown how calibration training often results in measurable improvements in accuracy and predictive power when it comes to probability assessments from humans. (And, at the end of the day, every decision is informed by probability assessments whether we realize it or not.) Thus, with calibration training, CRE analysts and experts can not only use their experience and wisdom, but quantify it and turn it into a more useful variable. (Click here for more information on Calibration Training.)
Including calibrated estimates can take one of the biggest weaknesses firms face and turn it into a key, valuable strength.
Putting It All Together: Producing an ROI-Boosting Commercial Real Estate Model
How do you overcome this challenge? Unfortunately, there’s no magic button or piece of software that you can buy off the shelf to do it for you. A well-built CRE model, incorporating the right measurements and a few basic statistical concepts based on probabilistic assessments, is what will improve your chances of generating more ROI – and avoiding costly pitfalls that routinely befall other firms.
The good news is that CRE investors don’t need an overly-complicated monster of a model to make better investment decisions. Over the years we’ve taught companies how incorporating just a few basic statistical methods can improve decision-making over what they were doing at the time. Calibrating experts, incorporating probabilities into the equation, and conducting simulations can, just by themselves, create meaningful improvements.
Eventually, a CRE firm should get to the point where it has a custom, fully-developed commercial real estate model built around its specific needs, like the model mentioned previously that we built for our NYC client.
There are a few different ways to get to that point, but the ultimate goal is to be able to deliver actionable insights, like “Investment A is 35% more likely than Investment B at achieving X% ROI over the next six months,” or something to that effect.
It just takes going beyond the usual suspects: ill-fitting variables, uncalibrated human judgment, and doing what everyone else is doing because that’s just how it’s done.
Risk management methodology, until very recently, was based mostly on pseudo-quantitative tools like risk matrices. The use of these tools has actually introduced more error into decision-making than they removed, as research has shown, and organizations are steadily coming around to more scientific quantitative methods – like Applied Information Economics (AIE). AIE is prominently cited in a new piece in the ISACA Journal, the publication of ISACA, a nonprofit, independent association that advocates for professionals involved in information security, assurance, risk management and governance.
The feature piece doesn’t hide the lede. The author says, in the opening paragraph, what Doug has been preaching for years: that “rick matrices do not really work. Worse, they lead to a false sense of security.” This was one of the main themes Doug talks about in The Failure of Risk Management, the second edition of which that is due for publication this year. The article sums up several of the main reasons Doug and others have given as to why risk matrices don’t work, ranging from lacking clear definitions to a failure to assign meaningful probabilities and cognitive biases that lead to poor assessments of probability and risk.
After moving through explanations of various aspects of effective risk models – i.e. tools like decomposition, Monte Carlo simulations, and the like – the author of the piece concludes with a simple statement that sums up the gist of what Applied Information Economics is designed to do: “There are better alternatives to risk matrices, and, with a little time and effort, it is possible to manage risk using terminology and methods that everyone can, at least intuitively, understand.”
Many things seem impossible to measure – so-called “intangibles” like employee engagement, innovation, customer satisfaction, transparency, and more – but with the right mindset and approach, you can measure anything. That’s the lesson of Doug’s book How to Measure Anything: Finding the Value of Intangibles in Business, and that’s the focus of his public lecture at the University of Bonn in Bonn, Germany on June 28, 2019.
In this lecture, Doug will discuss:
Three misconceptions that keep people from measuring what they should measure, and how to overcome them;
Why some common “quantitative” methods – including many based on subjective expert judgment – are ineffective;
How an organization can use practical statistical methods shown by scientific research to be more effective than anything else.
The lecture is hosted by the university’s Institute of Crop Science and Resource Conservation, which studies how to improve agriculture practices in Germany and around the world. Doug previously worked in this area when he helped the United Nations Environmental Program (UNEP) determine how to measure the impact of and modify restoration efforts in the Mongolian desert. You can view that report here. You can also view the official page for the lecture on the university’s website here.
In every industry, the risk of cyber attack is growing.
In 2015, a team of researchers forecasted that the maximum number of records that could be exposed in breaches – 200 million – would increase by 50% from then to 2020. According to the Identity Theft Resource Center, the number of records exposed in 2018was nearly 447 million – well over 50%. By 2021, damages from cybersecurity breacheswill cost organizations $6 trillion a year. In 2017, breaches cost global companies an average of $3.6 million, according to the Ponemon Institute.
It’s clear that this threat is sufficiently large to rank as one of an organization’s most prominent risks. To this end, corporations have entire cybersecurity risk programs in place to attempt to identify and mitigate as much risk as possible.
The foundation of accurate cybersecurity risk analysis begins with knowing what is out there. If you can’t identify the threats, you can’t assess their probabilities – and if you can’t assess their probabilities, your organization may be exposed by a critical vulnerability that won’t make itself known until it’s too late.
Cybersecurity threats may vary in specific from entity to entity, but in general, there are several common dangers that may be flying under the radar – and may be some you haven’t seen coming until now.
A Company’s Frontline Defense Isn’t Keeping Up the Pace
Technology is advancing at a more rapid rate than at any other point in human history: concepts such as cloud computing, machine learning, artificial intelligence, and Internet of Things (IoT) provide unprecedented advantages, but also introduce distinct vulnerabilities.
This rapid pace requires that cybersecurity technicians stay up to speed on the latest threats and mitigation techniques, but this often doesn’t occur. In a recent survey of IT professionals conducted by (ISC)^2, 43% indicated that their organization fails to provide adequate ongoing security training.
Unfortunately, leadership in companies large and small have traditionally been reluctant to invest in security training. The primary reason is mainly psychological; decision-makers tend to view IT investment in general as an expense that should be limited as much as possible, rather than as a hedge against the greater cost of failure.
Part of the reason why this phenomenon exists is due to how budgets are structured. IT investment adds to operational cost. Decision-makers – especially those in the MBA generation – are trained to reduce operational costs as much as possible in the name of greater efficiency and higher short-term profit margins. This mindset can cause executives to not look at IT investments as what they are: the price of mitigating greater costs.
Increases in IT security budgets also aren’t pegged to the increase of a company’s exposure, which isn’t static but fluctuates (and, in today’s world of increasingly-sophisticated threats, often increases).
The truth is, of course, that investing in cybersecurity may not make a company more money – a myopic view – it can keep a company from losing more money.
Another threat closely related to the above is how decision-makers tend to view probabilities. Research shows that decision-makers often overlook the potential cost of a negative event – like a data breach – in favor of its relatively-low probability (i.e. “It hasn’t happened before, or it probably won’t happen, so we don’t have to worry as much about it.”). These are called tail risks, risks that have disproportionate costs to their probabilities. In other words, they may not happen as frequently, but when they do, the consequences are often catastrophic.
There’s also a significant shortfall in cybersecurity professionals that is inducing more vulnerability into organizations that already are stressed to their maximum capacity. Across the globe, there are 2.93 million fewer workers than are needed. In North America, that number, in 2018, was just under 500,000.
Nearly a quarter of respondents in the aforementioned (ISC)^2 survey said they had a “significant shortage” in cybersecurity staff. Only 3% said they had “too many” workers. Overall, 63% of companies reported having fewer workers than they needed. And 59% said they were at “extreme or moderate risk” due to their shortage. (Yet, 43% said they were either going to not hire any new workers or even decrease the number of security personnel on their rosters.)
A combination of less training, inadequate budgets, and fewer workers all contribute to a major threat to security that many organizations fail to appreciate.
Threats from Beyond Borders Are Difficult to Assess – and Are Increasing
Many cybersecurity professionals correctly identify autonomous individuals and entities as a key threat – the stereotypical hacker or a team within a criminal organization. However, one significant and overlooked vector is the threat posed by other nations and foreign non-state actors.
China, Russia, and Iran are at the forefront of countries that leverage hacking in a state-endorsed effort to gain access to proprietary technology and data. In 2017, China implemented a law requiring any firm operating in China to store their data on servers physically located within the country, creating a significant risk of the information being accessed inappropriately. China also takes advantage of academic partnerships that American universities enjoy with numerous companies to access confidential data, tainting what should be the purest area of technological sharing and innovation.
In recent years, Russia has noticeably increased its demand to review the source code for any foreign technology being sold or used within its borders. Finally, Iran contains numerous dedicated hacking groups with defined targets, such as the aerospace industry, energy companies, and defense firms.
More disturbing than the source of these attacks are the pathways they use to acquire this data – including one surprising method. A Romanian source recently revealed to Business Insider that when large companies sell outdated (but still functional) servers, the information isn’t always completely wiped. The source in question explained that he’d been able to procure an almost complete database from a Dutch public health insurance system; all of the codes, software, and procedures for traffic lights and railway signaling for several European cities; and an up-to-date employee directory (including access codes and passwords) for a major European aerospace manufacturer from salvaged equipment.
A common technique used by foreign actors in general, whether private or state-sponsored, is to use legitimate front companies to purchase or partner with other businesses and exploit the access afforded by these relationships. Software supply chain attacks have significantly increased in recent years, with seven significant events occurring in 2017, compared to only four between 2014 and 2016. FedEx and Maersk suffered approximately $600 million in losses from a single such attack.
The threat from across borders can be particularly difficult to assess due to distance, language barriers, a lack of knowledge about the local environment, and other factors. It is, nonetheless, something that has to be taken into consideration by a cybersecurity program – and yet often isn’t.
The Biggest Under-the-Radar Risk Is How You Assess Risks
While identifying risks is the foundation of cybersecurity, appropriately analyzing them is arguably more important. Many commonly used methods of risk analysis can actually obscure and increase risk rather than expose and mitigate it. In other words, many organizations are vulnerable to the biggest under-the-radar threat of them all: a broken risk management system.
Qualitative and pseudo-quantitative methods often create what Doug Hubbard calls the “analysis placebo effect,”(add footnote) where tactics are perceived to be improvements but offer no tangible benefits. This can increase vulnerabilities by instilling a false sense of confidence, and psychologists have shown that this can occur even when the tactics themselves increase estimate errors. Two months before a massive cyber attack rocked Atlanta in 2018, a risk assessment revealed various vulnerabilities, but the fix actions to address these fell short of actually resolving the city’s exposure—although officials were confident they had adequately addressed the risk.
Techniques such as heat maps, risk matrices, and soft scoring often fail to inform an organization regarding which risks they should address and how they should do so. Experts indicate that “risk matrices should not be used for decisions of any consequence,<fn>Thomas, Philip & Bratvold, Reidar & Bickel, J. (2013). The Risk of Using Risk Matrices. SPE Economics & Management. 6. 10.2118/166269-MS.</fn>” and they can be even “worse than useless.<fn>Anthony (Tony) Cox, L. (2008), What’s Wrong with Risk Matrices?. Risk Analysis, 28: 497-512. doi:10.1111/j.1539-6924.2008.01030.x</fn>” Studies have repeatedly shown, in numerous venues, that collecting too much data, collaborating beyond a certain point, and relying on structured, qualitative decision analyses consistently produce worse results than if these actions had been avoided.
It’s easy to assume that many aspects of cybersecurity are inestimable, but we believe that anything can be measured. If it can be measured, it can be assessed and addressed appropriately. A quantitative model that circumvents overconfidence commonly seen with qualitative measures, uses properly-calibrated expert assessments, knows what information is most valuable and what isn’t, and is built on a comprehensive, multi-disciplinary framework can provide actionable data to guide appropriate decisions.
Bottom line: not all cybersecurity threats are readily apparent, and the most dangerous ones can easily be ones you underestimate, or don’t see coming at all. Knowing which factors to measure and how to quantify them can help you identify the most pressing vulnerabilities, which is the cornerstone of effective cybersecurity practices
What follows is a tale that, for business people, reads like a Shakespearean tragedy – or a Stephen King horror novel. It starts with the recent history-setting success of Avengers: Endgame and the notion that an idea has value – and if you don’t see it or won’t realize it, someone else will.
The year is 1998. As explained in this Wall Street Journal piece, Sony Pictures wanted to buy the rights to produce Spider-Man movies. Marvel Entertainment, who owned the rights, needed cash because they had just came out of bankruptcy. So, Marvel essentially told Sony that not only could it have the rights to Spider-Man, it could have the rights to almost every Marvel character for the low-low sum of $25 million.
These Marvel characters? They included Iron Man, Thor, Black Panther, and others. You may recognize those names, unless you’ve sworn off entertainment altogether for the past decade.
Sony said “No thanks, we just want Spider-Man,” and only paid $10 million in cash.
Eleven years and 22 movies later, the Marvel Cinematic Universe (MCU) has grossed a staggering $19.9 billion (as of 4/30/2019) – and they’re not done making movies, with plenty more on the way.
Sony’s decision was an epically bad one, of course, but only in hindsight. There’s no guarantee that even if they had bought the rights that they would’ve had the same success. Besides, there’s no way they could’ve predicted just how valuable the franchise would turn out to be. After all, at the time, the cinematic prospects for many of the characters that were for sale were low, to say the least. Part of that is due to a decade-long slide in quality and popularity for Marvel in the 1990s that eventually lead to its bankruptcy.
Measuring value for an idea is impossible. You just can’t predict what movies – or books, or songs, or works of art, or ideas in general – will be successful…right?
Finding the Next Hit: Measuring the Potential Value of an Idea
One pervasive belief is that you can’t measure or quantify an intangible thing like an idea, like a movie. People believe that you can only quantify tangible things, and even then, it’s difficult to forecast what will happen.
Ideas, though, can be measured just like anything else. Can you put an exact number on an intangible concept, like whether or not a movie will be a success? No – but that’s not what measurement and quantification are, really.
At its most basic, measurement is just reducing the amount of uncertainty you have about something. You don’t have to put an exact number on a concept to be more certain about it. For example, Sony Pictures wasn’t certain how much a Spider-Man movie would make, but it was confident that the rights were worth more than $10 million.
One of the most successful superhero movies in the 1990’s – Batman Forever, starring Val Kilmer, Jim Carrey, and Tommy Lee Jones – raked in $336.5 million on a then-massive budget of $100 million.
If we’re Sony and we think Spider-Man is roughly as popular as Batman, we can reasonably guess that a Spider-Man movie could do almost as well. (Even a universally-panned superhero movie, Batman & Robin, grossed $238.2 million on a budget of $125 million.) We can do a quick-and-dirty proxy of popularity by comparing the total number of copies sold for each franchise.
Unfortunately there’s a huge gap in data for most comics between 1987 and the 2000’s. No matter. We can use the last year prior to 1998 in which there was industry data for both characters. Roughly 150,000 copies of Batman comics were sold in 1987, versus roughly 170,000 copies of Spider-Man.
Conclusion: it’s fair to say that Spider-Man, in 1998, was probably as popular as Batman was before Batman’s first release, the simply-named Batman in 1989 with Michael Keaton and a delightfully-twisted Jack Nicholson. Thus, Sony was making a good bet when it bought the rights to Spider-Man in 1998.
Uncertainty, then, can be reduced. The more you reduce uncertainty through measurement, the better the decision will be, all other things considered equal. You don’t need an exact number to make a decision; you just have to get close enough.
So how can we take back-of-the-envelope math to the next level and further reduce uncertainty about ideas?
Creating a Probabilistic Model for Intangible Ideas
Back-of-the-envelope is well and good if you want to take a crack at narrowing down your initial range of uncertainty. But if you want to further reduce uncertainty and increase the probability of making a good call, you’ll have to start calculating probability.
Normally, organizations like movie studios (and just about everyone else) turn to subject matter experts to assess the chances of something happening, or to evaluate the quality or value of something. These people often have years to decades of experience and have developed a habit of relying on their gut instinct when making decisions. Movie executives are no different.
Unfortunately, organizations often assume that expert judgment is the only real solution, or, if they concede the need for quantitative analysis, they often rely too much on the subjective element and not enough on the objective. This is due to a whole list of reasons people have for dismissing stats, math, analytics, and the like.
Doug Hubbard ran into this problem years ago when he tapped to do exactly what the Sony executives should’ve done in 1998: create a statistical model that will predict the movie projects most likely to succeed at the box office. He tells the story from his book How to Measure Anything: Finding the Value of “Intangibles” in Business:
The people who are paid to review movie projects are typically ex-producers, and they have a hard time imagining how an equation could outperform their judgment. In one particular conversation, I remember a script reviewer talking about the need for his “holistic” analysis of the entire movie project based on his creative judgment and years of experience. In his words, the work was “too complex for a mathematical model.”
Of course, Doug wasn’t going to leave it at that. He examined the past predictions about box office success for given projects that experts had made, along with how much these projects actually grossed, and he found no correlation between the two. In fact, projections overestimated the performance of a movie at the box office nearly 80% of the time – and underestimated performance only 20% of the time.
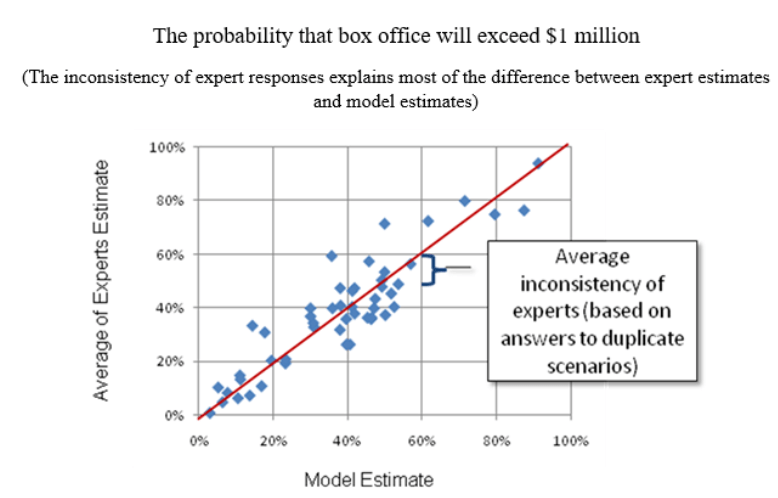
Figure 1 compares expert assessment and a model of expert estimates, using data points from small-budget indie films:
Figure 1: Comparison Between Expert Estimates and the Model Estimate
As Doug says, “If I had developed a random number generator that produced the same distribution of numbers as historical box office results, I could have predicted outcomes as well as the experts.”
He did, however, gain a few crucial insights from historical data. One was that there was a correlation between the distributor’s marketing budget for a movie and how well the movie performed at the box office. This led him to the final conclusion of his story:
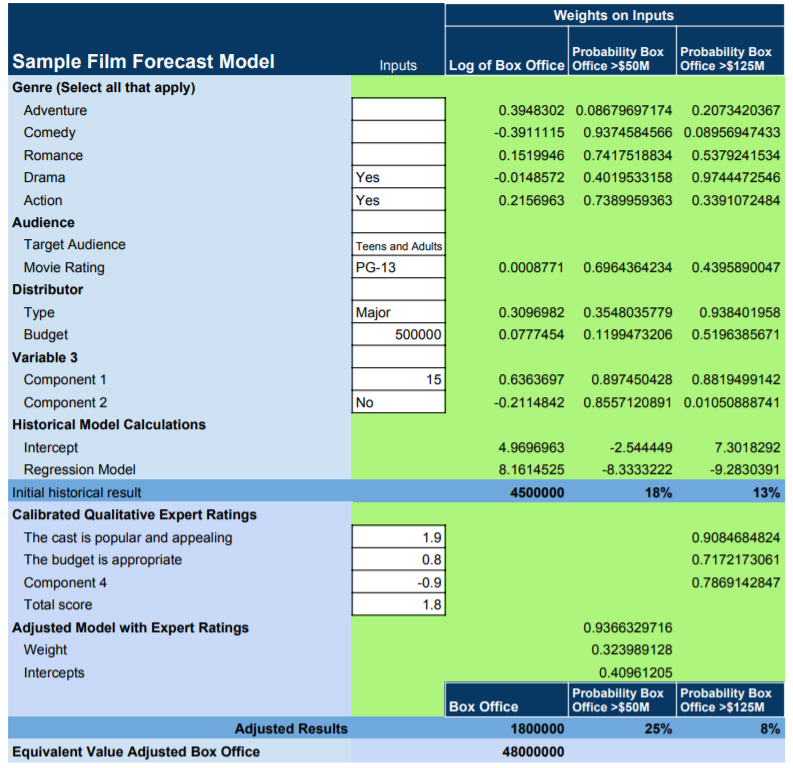
Using a few more variables, we created a model that had a…correlation with actual box office results. This was a huge improvement over the previous track record of the experts.
Was the model a crystal ball that made perfect, or even amazingly-accurate predictions? Of course not. But – and this is the entire point – the model reduced uncertainty in a way that the studio’s current methods could not. The studio in question increased its chances of hitting paydirt with a given project – which, given just how much of a gamble making a movie can be, is immensely valuable.
The process for creating a model is less complicated than you might think. If you understand the basic process, as shown below in Figure 2, you have a framework to measure anything:
Figure 2: Decision Analysis Process
At its core, a model takes variables – anything from distributor budget for movies to, say, technology adoption rate for business projects – and uses calibrated estimates, historical data, and a range of other factors to put values on them. Then, the model applies a variety of statistical methods that have been shown by research and experience to be valid and creates an output that can look like this in Figure 3 (the numbers are just an example) :
Figure 3: Sample Film Forecast Model
What’s the Next Big Hit?
The next big hit – whether it’s a movie, an advertising campaign, a political campaign, or a ground-breaking innovation in business – can be modeled beyond mere guesswork or even expert assessment. The trick – and really, the hard part – is figuring out how to measure the critical intangibles inherent to these abstract concepts. The problem today is that most quantitative models skip them altogether.
But intangibles are important. How much your average fan loves a character, and will spend hard-earned money to go to a movie theatre to see an upcoming film about, say, a biochemist-turned-vampire named Morbius, will ultimately help to determine success. Expressed in that desire – in any desire – are any number of innate human motivations and components of personality that can be measured.
(By the way, the aforementioned Morbius movie is being made by Sony as a part of the Marvel Cinematic Universe. Better late than never, although you don’t need a model to predict Morbius won’t gross as much as Avengers: Endgame, despite how cool the character may be.
In this world, precious few things are certain. But with a little math and a little ingenuity, you can measure anything – and if you can measure it, you can model and forecast it and get a much better idea of what will be the next great idea – and the next big hit.

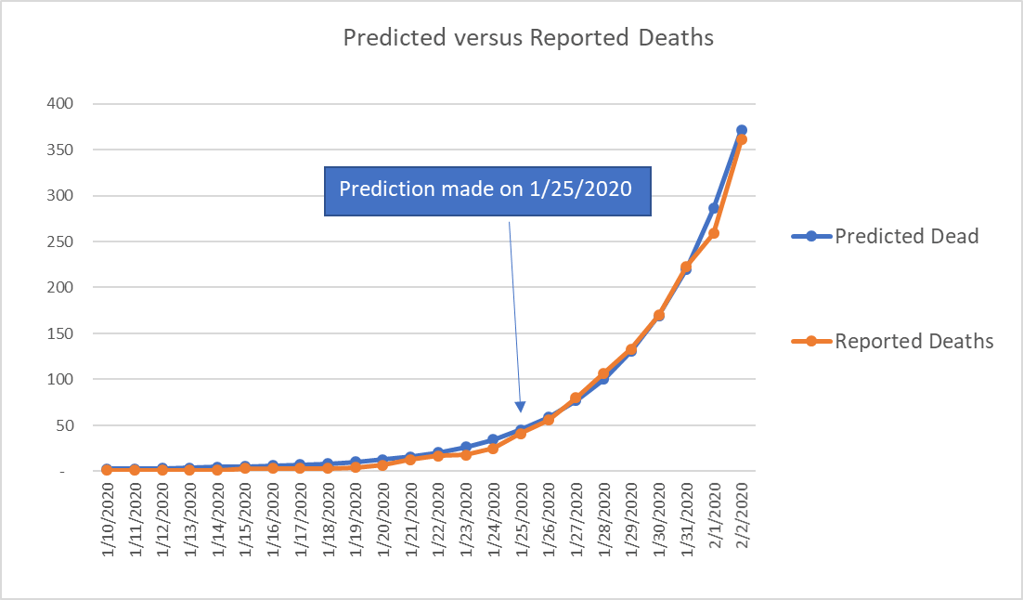
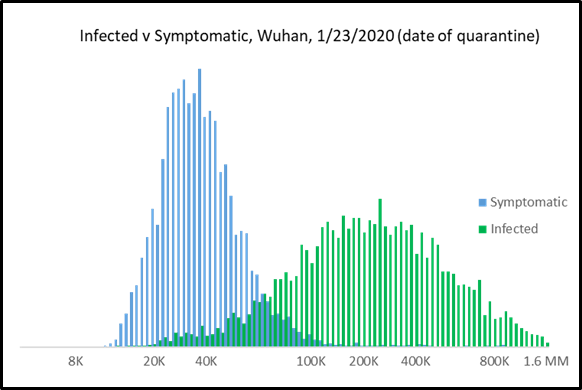
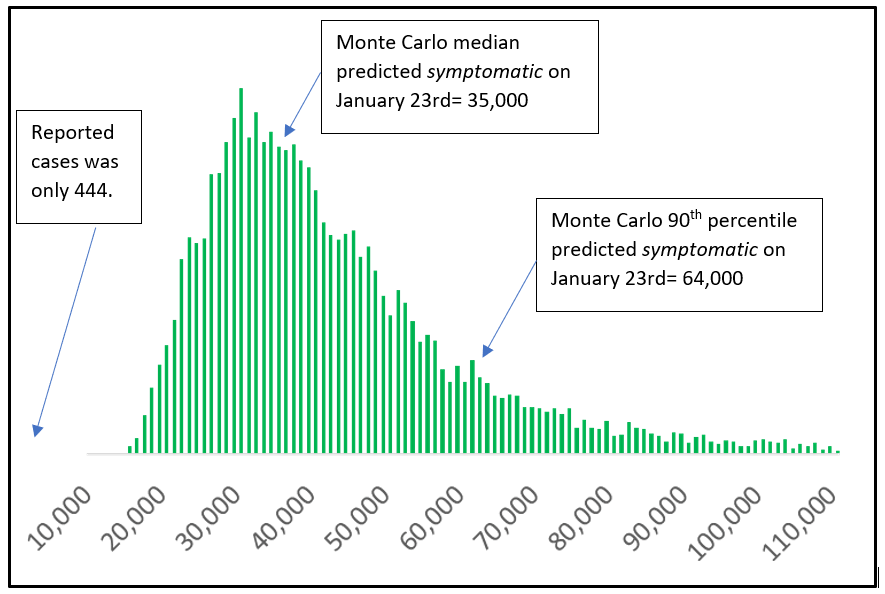
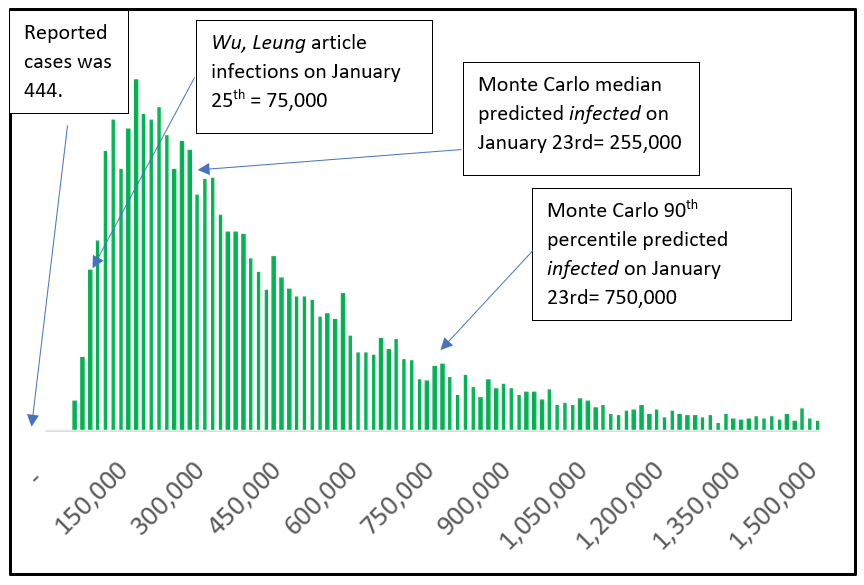
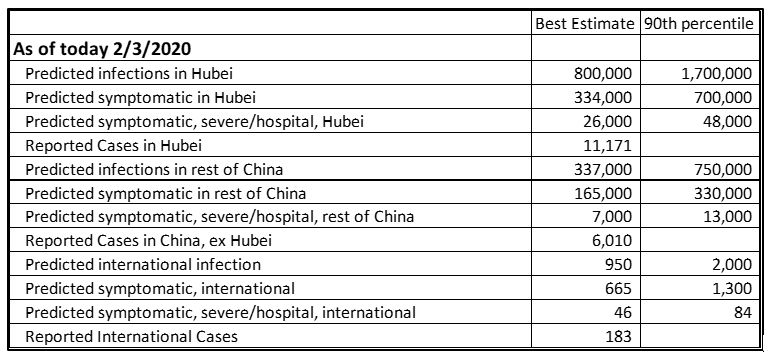

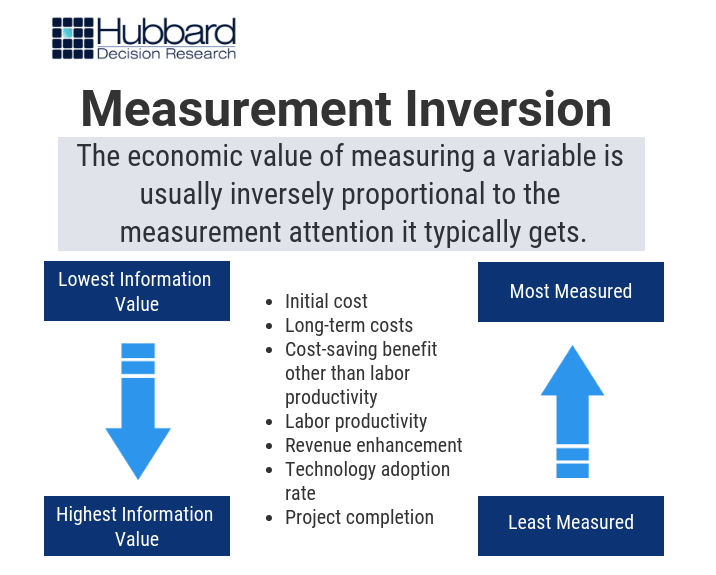
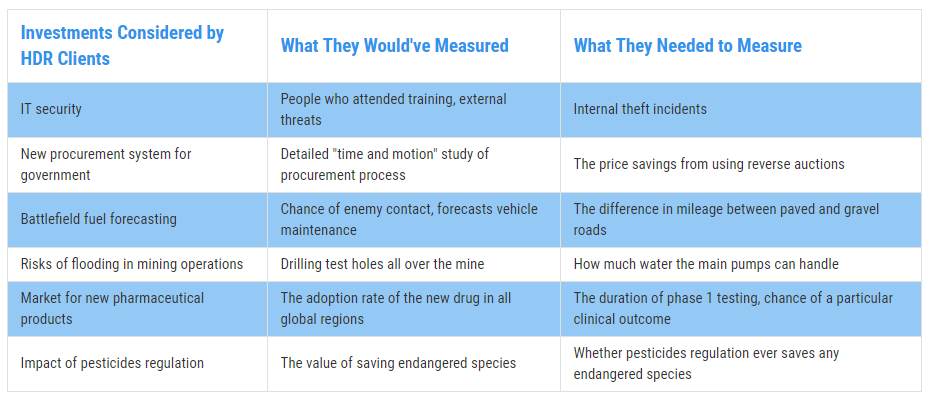


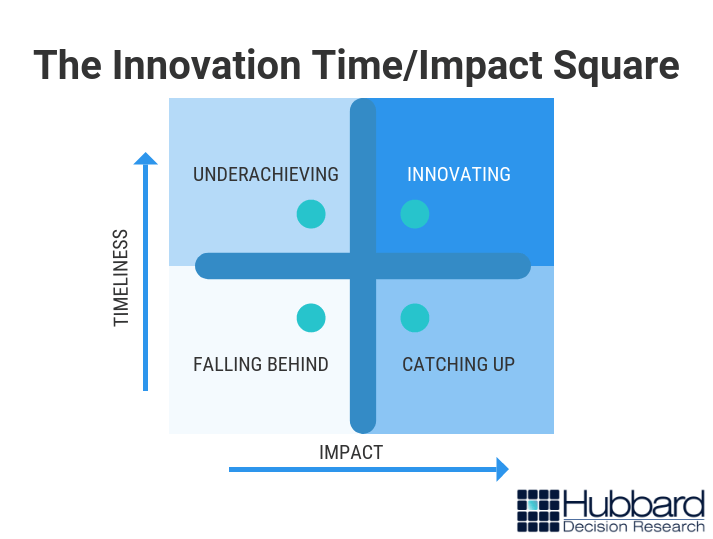


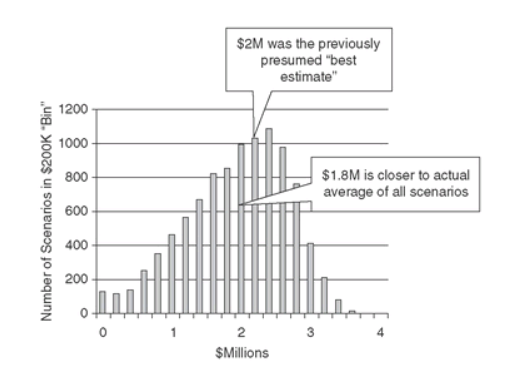

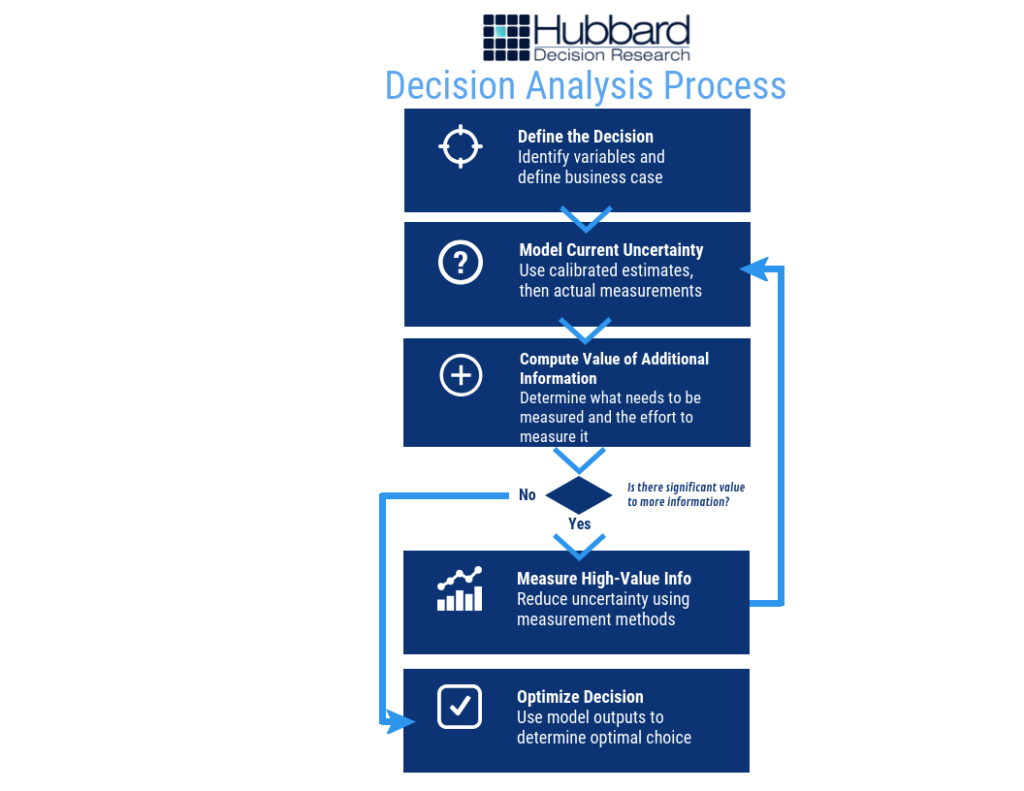


 Figure 2: Solving the Measurement Inversion Problem
Figure 2: Solving the Measurement Inversion Problem